 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXOR Mixup: Privacy-Preserving Data Augmentation for One-Shot Federated Learning
Paper and Code
Jun 09, 2020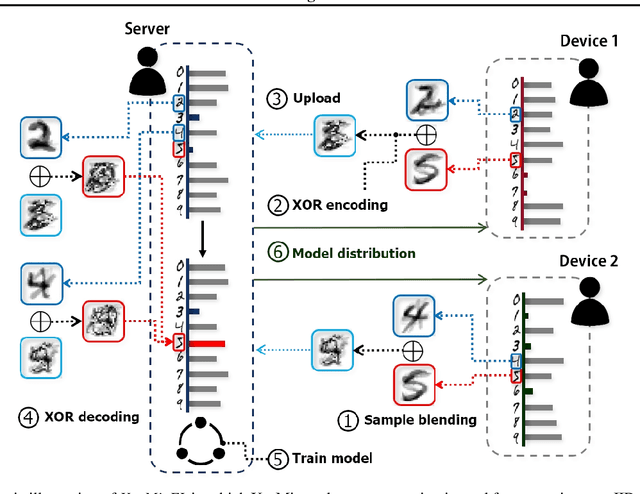
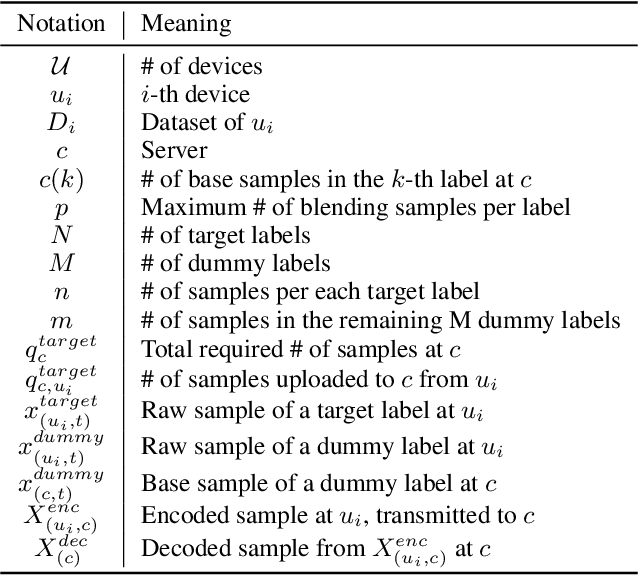


User-generated data distributions are often imbalanced across devices and labels, hampering the performance of federated learning (FL). To remedy to this non-independent and identically distributed (non-IID) data problem, in this work we develop a privacy-preserving XOR based mixup data augmentation technique, coined XorMixup, and thereby propose a novel one-shot FL framework, termed XorMixFL. The core idea is to collect other devices' encoded data samples that are decoded only using each device's own data samples. The decoding provides synthetic-but-realistic samples until inducing an IID dataset, used for model training. Both encoding and decoding procedures follow the bit-wise XOR operations that intentionally distort raw samples, thereby preserving data privacy. Simulation results corroborate that XorMixFL achieves up to 17.6% higher accuracy than Vanilla FL under a non-IID MNIST dataset.