 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXceptionTime: A Novel Deep Architecture based on Depthwise Separable Convolutions for Hand Gesture Classification
Paper and Code
Nov 09, 2019

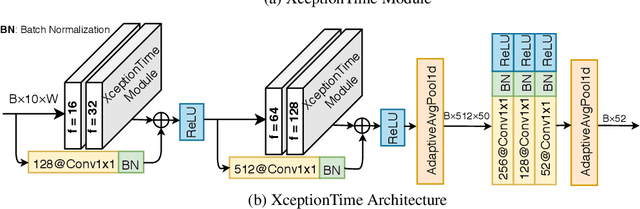

Capitalizing on the need for addressing the existing challenges associated with gesture recognition via sparse multichannel surface Electromyography (sEMG) signals, the paper proposes a novel deep learning model, referred to as the XceptionTime architecture. The proposed innovative XceptionTime is designed by integration of depthwise separable convolutions, adaptive average pooling, and a novel non-linear normalization technique. At the heart of the proposed architecture is several XceptionTime modules concatenated in series fashion designed to capture both temporal and spatial information-bearing contents of the sparse multichannel sEMG signals without the need for data augmentation and/or manual design of feature extraction. In addition, through integration of adaptive average pooling, Conv1D, and the non-linear normalization approach, XceptionTime is less prone to overfitting, more robust to temporal translation of the input, and more importantly is independent from the input window size. Finally, by utilizing the depthwise separable convolutions, the XceptionTime network has far fewer parameters resulting in a less complex network. The performance of XceptionTime is tested on a sub Ninapro dataset, DB1, and the results showed a superior performance in comparison to any existing counterparts. In this regard, 5:71% accuracy improvement, on a window size 200ms, is reported in this paper, for the first time.