 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Fields: Implicit Neural View-, Light- and Time-Image Interpolation
Paper and Code
Oct 01, 2020
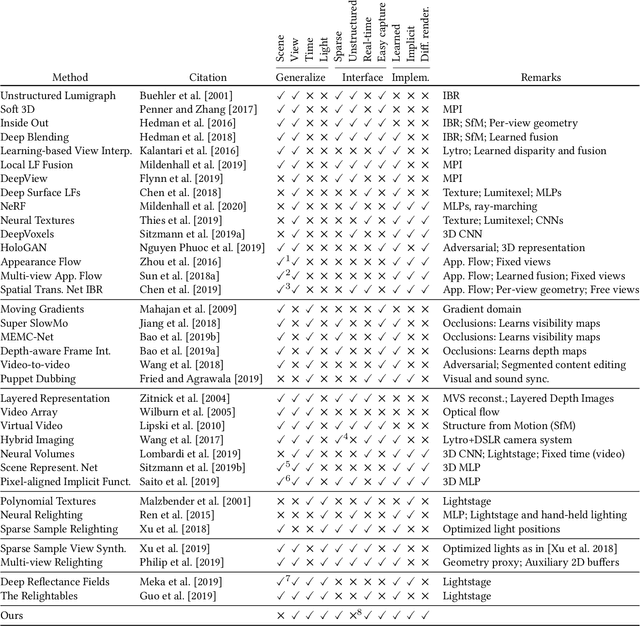
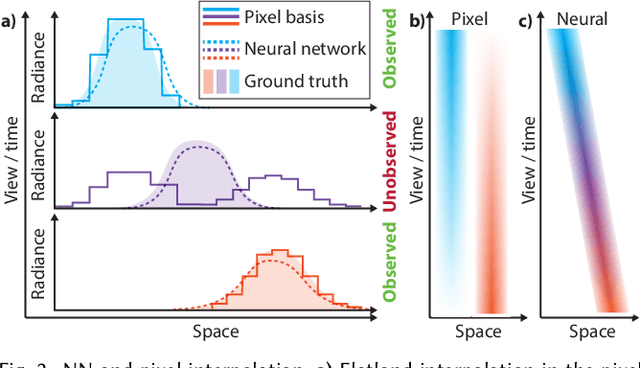
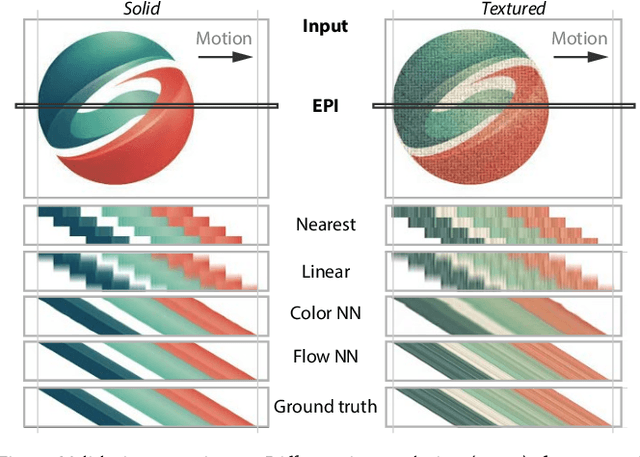
We suggest to represent an X-Field -a set of 2D images taken across different view, time or illumination conditions, i.e., video, light field, reflectance fields or combinations thereof-by learning a neural network (NN) to map their view, time or light coordinates to 2D images. Executing this NN at new coordinates results in joint view, time or light interpolation. The key idea to make this workable is a NN that already knows the "basic tricks" of graphics (lighting, 3D projection, occlusion) in a hard-coded and differentiable form. The NN represents the input to that rendering as an implicit map, that for any view, time, or light coordinate and for any pixel can quantify how it will move if view, time or light coordinates change (Jacobian of pixel position with respect to view, time, illumination, etc.). Our X-Field representation is trained for one scene within minutes, leading to a compact set of trainable parameters and hence real-time navigation in view, time and illumination.