 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiBERT models: deep transfer learning for many languages
Paper and Code
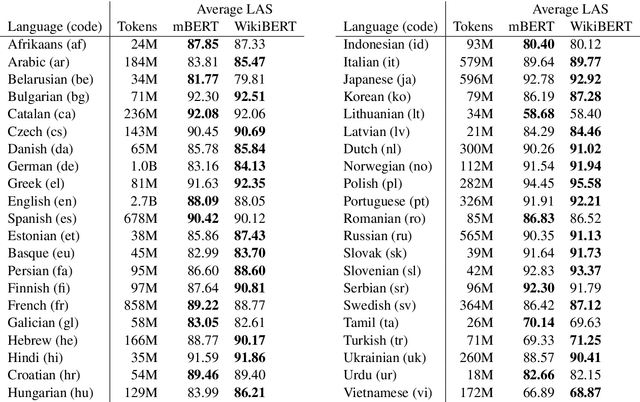
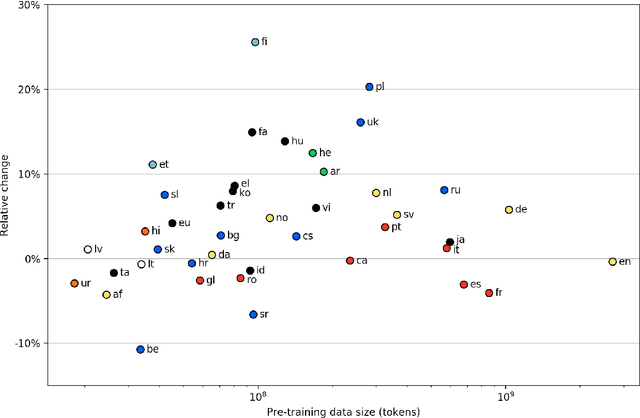
Deep neural language models such as BERT have enabled substantial recent advances in many natural language processing tasks. Due to the effort and computational cost involved in their pre-training, language-specific models are typically introduced only for a small number of high-resource languages such as English. While multilingual models covering large numbers of languages are available, recent work suggests monolingual training can produce better models, and our understanding of the tradeoffs between mono- and multilingual training is incomplete. In this paper, we introduce a simple, fully automated pipeline for creating language-specific BERT models from Wikipedia data and introduce 42 new such models, most for languages up to now lacking dedicated deep neural language models. We assess the merits of these models using the state-of-the-art UDify parser on Universal Dependencies data, contrasting performance with results using the multilingual BERT model. We find that UDify using WikiBERT models outperforms the parser using mBERT on average, with the language-specific models showing substantially improved performance for some languages, yet limited improvement or a decrease in performance for others. We also present preliminary results as first steps toward an understanding of the conditions under which language-specific models are most beneficial. All of the methods and models introduced in this work are available under open licenses from https://github.com/turkunlp/wikibert.