 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Stable Learning Works? A Theory of Covariate Shift Generalization
Paper and Code
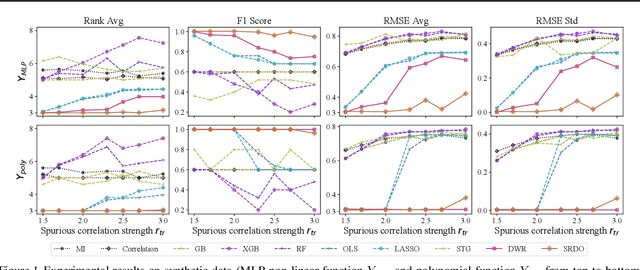
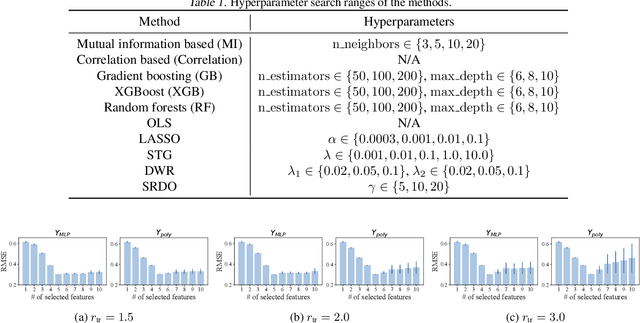
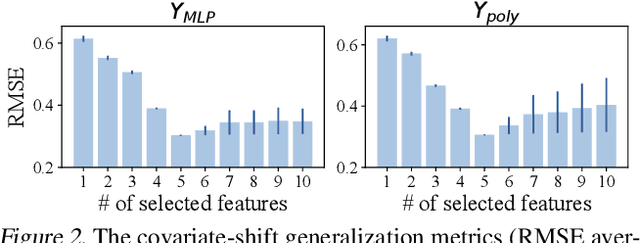
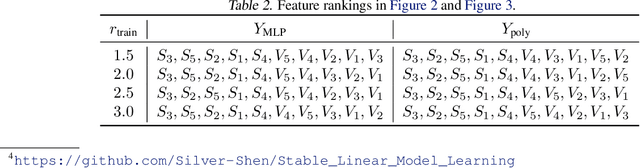
Covariate shift generalization, a typical case in out-of-distribution (OOD) generalization, requires a good performance on the unknown testing distribution, which varies from the accessible training distribution in the form of covariate shift. Recently, stable learning algorithms have shown empirical effectiveness to deal with covariate shift generalization on several learning models involving regression algorithms and deep neural networks. However, the theoretical explanations for such effectiveness are still missing. In this paper, we take a step further towards the theoretical analysis of stable learning algorithms by explaining them as feature selection processes. We first specify a set of variables, named minimal stable variable set, that is minimal and optimal to deal with covariate shift generalization for common loss functions, including the mean squared loss and binary cross entropy loss. Then we prove that under ideal conditions, stable learning algorithms could identify the variables in this set. Further analysis on asymptotic properties and error propagation are also provided. These theories shed light on why stable learning works for covariate shift generalization.