 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhether and When does Endoscopy Domain Pretraining Make Sense?
Paper and Code
Mar 30, 2023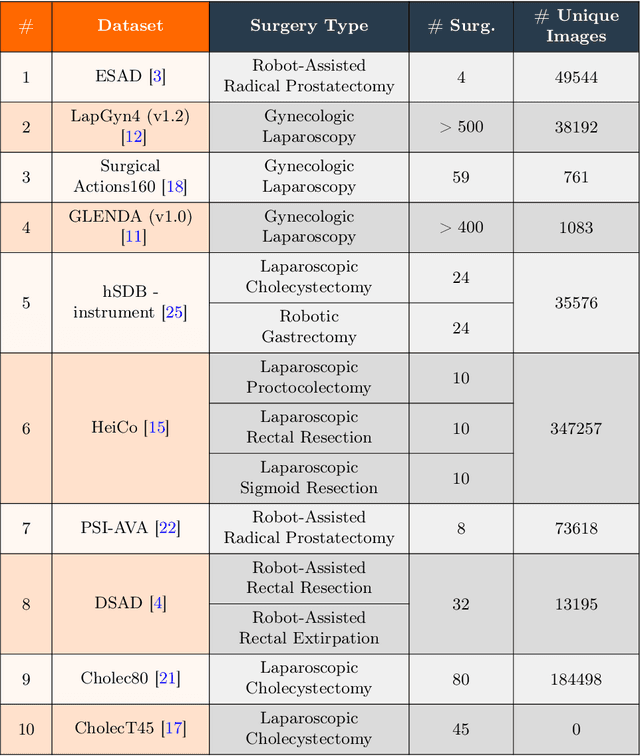
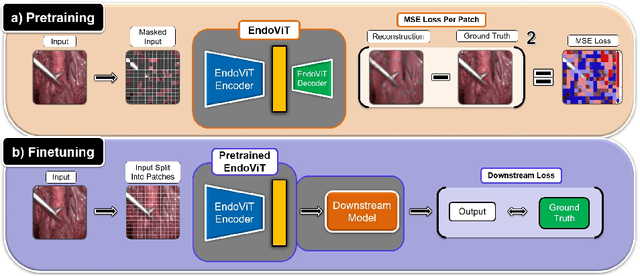

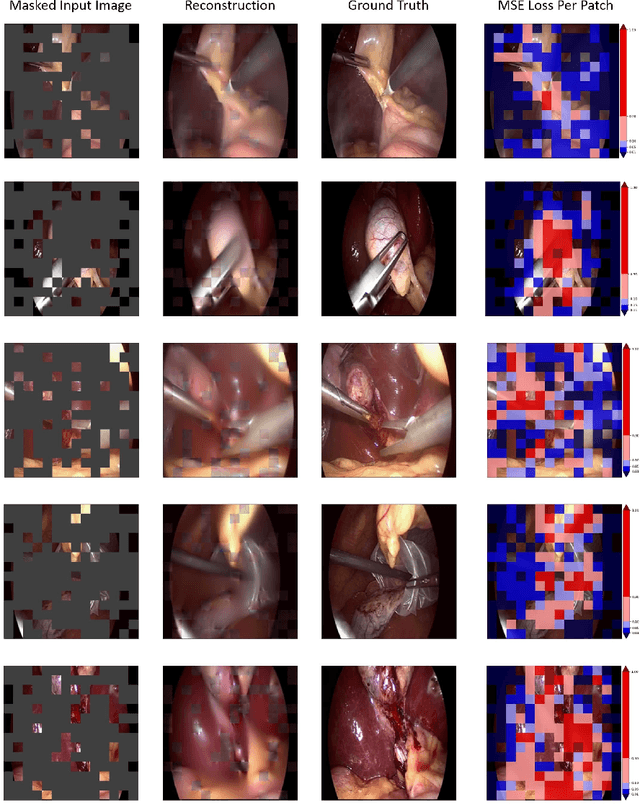
Automated endoscopy video analysis is a challenging task in medical computer vision, with the primary objective of assisting surgeons during procedures. The difficulty arises from the complexity of surgical scenes and the lack of a sufficient amount of annotated data. In recent years, large-scale pretraining has shown great success in natural language processing and computer vision communities. These approaches reduce the need for annotated data, which is always a concern in the medical domain. However, most works on endoscopic video understanding use models pretrained on natural images, creating a domain gap between pretraining and finetuning. In this work, we investigate the need for endoscopy domain-specific pretraining based on downstream objectives. To this end, we first collect Endo700k, the largest publicly available corpus of endoscopic images, extracted from nine public Minimally Invasive Surgery (MIS) datasets. Endo700k comprises more than 700,000 unannotated raw images. Next, we introduce EndoViT, an endoscopy pretrained Vision Transformer (ViT). Through ablations, we demonstrate that domain-specific pretraining is particularly beneficial for more complex downstream tasks, such as Action Triplet Detection, and less effective and even unnecessary for simpler tasks, such as Surgical Phase Recognition. We will release both our code and pretrained models upon acceptance to facilitate further research in this direction.