 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Weak Becomes Strong: Robust Quantification of White Matter Hyperintensities in Brain MRI scans
Paper and Code
Apr 12, 2020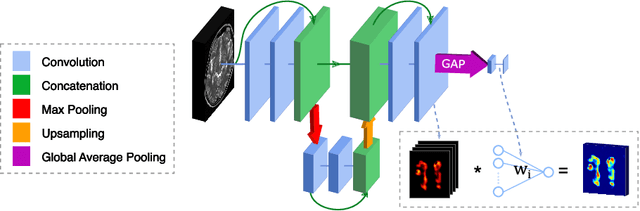
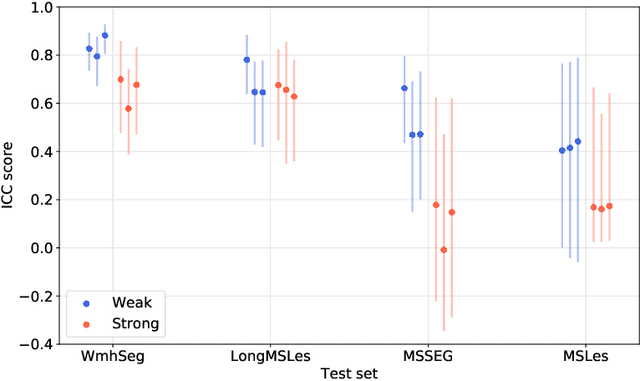
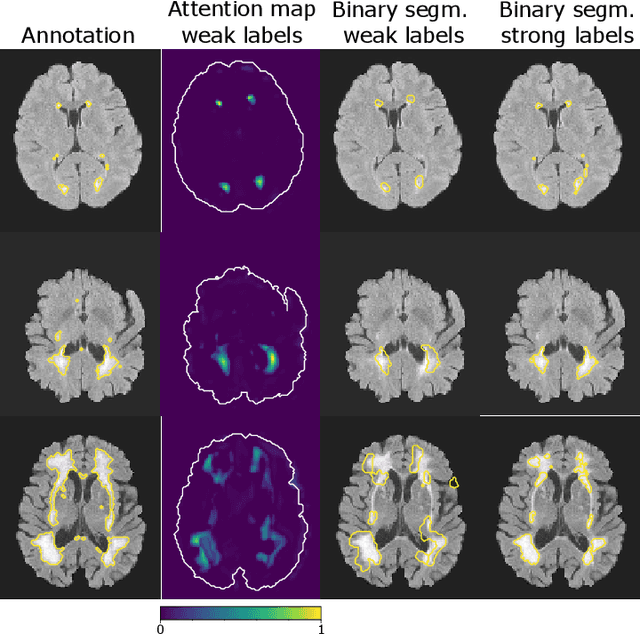
To measure the volume of specific image structures, a typical approach is to first segment those structures using a neural network trained on voxel-wise (strong) labels and subsequently compute the volume from the segmentation. A more straightforward approach would be to predict the volume directly using a neural network based regression approach, trained on image-level (weak) labels indicating volume. In this article, we compared networks optimized with weak and strong labels, and study their ability to generalize to other datasets. We experimented with white matter hyperintensity (WMH) volume prediction in brain MRI scans. Neural networks were trained on a large local dataset and their performance was evaluated on four independent public datasets. We showed that networks optimized using only weak labels reflecting WMH volume generalized better for WMH volume prediction than networks optimized with voxel-wise segmentations of WMH. The attention maps of networks trained with weak labels did not seem to delineate WMHs, but highlighted instead areas with smooth contours around or near WMHs. By correcting for possible confounders we showed that networks trained on weak labels may have learnt other meaningful features that are more suited to generalization to unseen data. Our results suggest that for imaging biomarkers that can be derived from segmentations, training networks to predict the biomarker directly may provide more robust results than solving an intermediate segmentation step.