 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Factors Affect Multi-Modal In-Context Learning? An In-Depth Exploration
Paper and Code
Oct 27, 2024
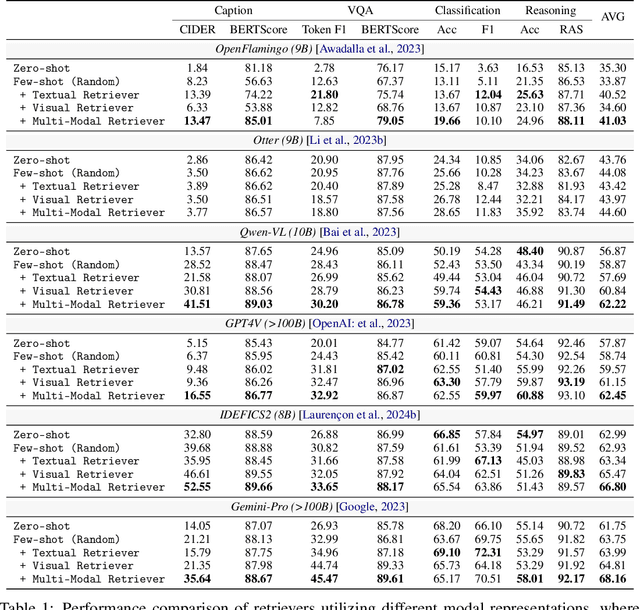
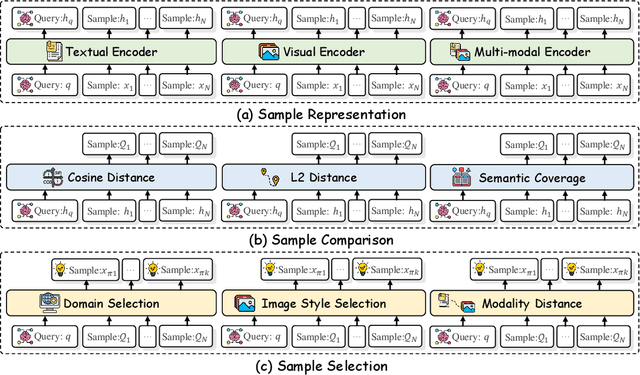

Recently, rapid advancements in Multi-Modal In-Context Learning (MM-ICL) have achieved notable success, which is capable of achieving superior performance across various tasks without requiring additional parameter tuning. However, the underlying rules for the effectiveness of MM-ICL remain under-explored. To fill this gap, this work aims to investigate the research question: "What factors affect the performance of MM-ICL?'' To this end, we investigate extensive experiments on the three core steps of MM-ICL including demonstration retrieval, demonstration ordering, and prompt construction using 6 vision large language models and 20 strategies. Our findings highlight (1) the necessity of a multi-modal retriever for demonstration retrieval, (2) the importance of intra-demonstration ordering over inter-demonstration ordering, and (3) the enhancement of task comprehension through introductory instructions in prompts. We hope this study can serve as a foundational guide for optimizing MM-ICL strategies in future research.