 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat a Nerd! Beating Students and Vector Cosine in the ESL and TOEFL Datasets
Paper and Code
Mar 29, 2016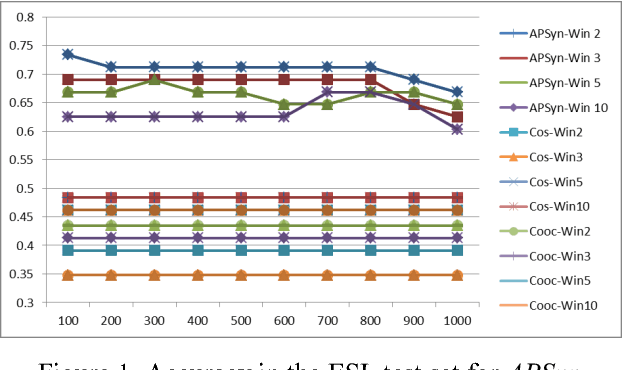
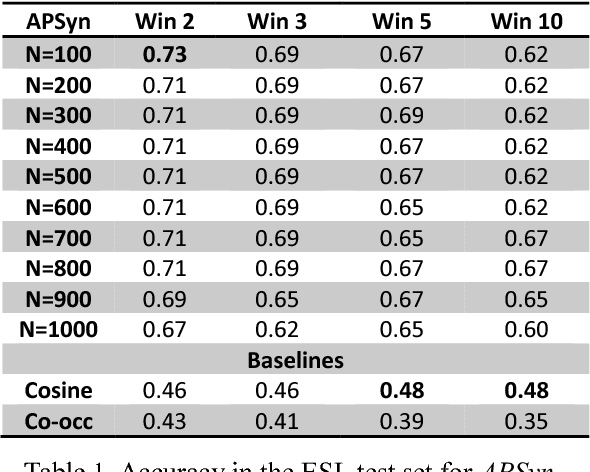


In this paper, we claim that Vector Cosine, which is generally considered one of the most efficient unsupervised measures for identifying word similarity in Vector Space Models, can be outperformed by a completely unsupervised measure that evaluates the extent of the intersection among the most associated contexts of two target words, weighting such intersection according to the rank of the shared contexts in the dependency ranked lists. This claim comes from the hypothesis that similar words do not simply occur in similar contexts, but they share a larger portion of their most relevant contexts compared to other related words. To prove it, we describe and evaluate APSyn, a variant of Average Precision that, independently of the adopted parameters, outperforms the Vector Cosine and the co-occurrence on the ESL and TOEFL test sets. In the best setting, APSyn reaches 0.73 accuracy on the ESL dataset and 0.70 accuracy in the TOEFL dataset, beating therefore the non-English US college applicants (whose average, as reported in the literature, is 64.50%) and several state-of-the-art approaches.