 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWangLab at MEDIQA-M3G 2024: Multimodal Medical Answer Generation using Large Language Models
Paper and Code
Apr 22, 2024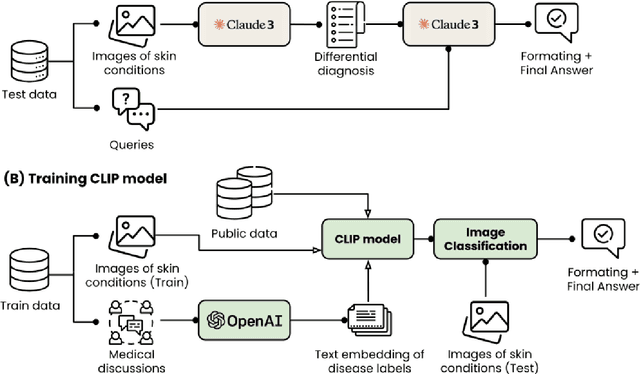
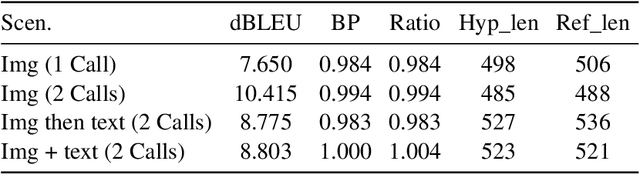
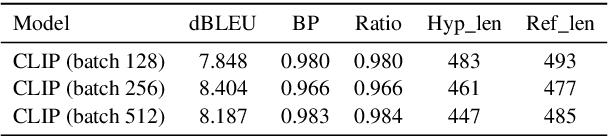

This paper outlines our submission to the MEDIQA2024 Multilingual and Multimodal Medical Answer Generation (M3G) shared task. We report results for two standalone solutions under the English category of the task, the first involving two consecutive API calls to the Claude 3 Opus API and the second involving training an image-disease label joint embedding in the style of CLIP for image classification. These two solutions scored 1st and 2nd place respectively on the competition leaderboard, substantially outperforming the next best solution. Additionally, we discuss insights gained from post-competition experiments. While the performance of these two solutions have significant room for improvement due to the difficulty of the shared task and the challenging nature of medical visual question answering in general, we identify the multi-stage LLM approach and the CLIP image classification approach as promising avenues for further investigation.