 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSEGAN: Visual Speech Enhancement Generative Adversarial Network
Paper and Code
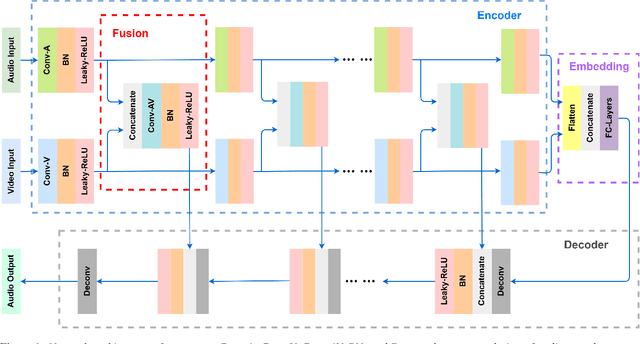

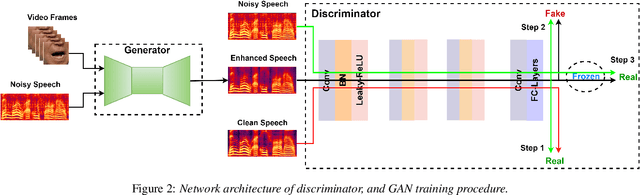
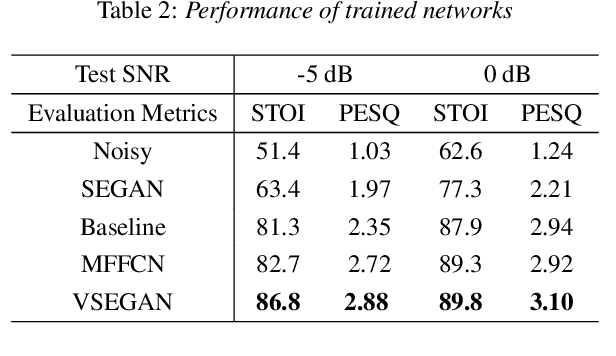
Speech enhancement is an essential task of improving speech quality in noise scenario. Several state-of-the-art approaches have introduced visual information for speech enhancement,since the visual aspect of speech is essentially unaffected by acoustic environment. This paper proposes a novel frameworkthat involves visual information for speech enhancement, by in-corporating a Generative Adversarial Network (GAN). In par-ticular, the proposed visual speech enhancement GAN consistof two networks trained in adversarial manner, i) a generator that adopts multi-layer feature fusion convolution network to enhance input noisy speech, and ii) a discriminator that attemptsto minimize the discrepancy between the distributions of the clean speech signal and enhanced speech signal. Experiment re-sults demonstrated superior performance of the proposed modelagainst several state-of-the-art