 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisDA: The Visual Domain Adaptation Challenge
Paper and Code
Nov 29, 2017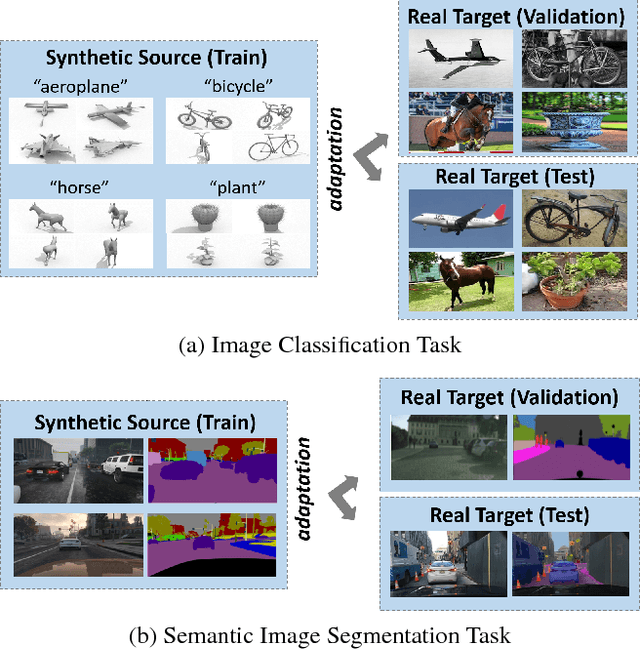

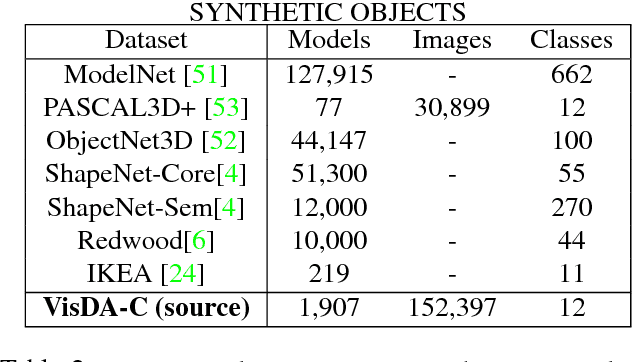

We present the 2017 Visual Domain Adaptation (VisDA) dataset and challenge, a large-scale testbed for unsupervised domain adaptation across visual domains. Unsupervised domain adaptation aims to solve the real-world problem of domain shift, where machine learning models trained on one domain must be transferred and adapted to a novel visual domain without additional supervision. The VisDA2017 challenge is focused on the simulation-to-reality shift and has two associated tasks: image classification and image segmentation. The goal in both tracks is to first train a model on simulated, synthetic data in the source domain and then adapt it to perform well on real image data in the unlabeled test domain. Our dataset is the largest one to date for cross-domain object classification, with over 280K images across 12 categories in the combined training, validation and testing domains. The image segmentation dataset is also large-scale with over 30K images across 18 categories in the three domains. We compare VisDA to existing cross-domain adaptation datasets and provide a baseline performance analysis using various domain adaptation models that are currently popular in the field.