 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Similarity and Alignment Learning on Partial Video Copy Detection
Paper and Code
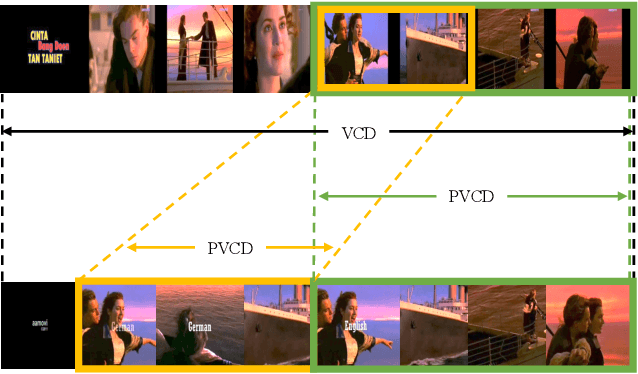



Existing video copy detection methods generally measure video similarity based on spatial similarities between key frames, neglecting the latent similarity in temporal dimension, so that the video similarity is biased towards spatial information. There are methods modeling unified video similarity in an end-to-end way, but losing detailed partial alignment information, which causes the incapability of copy segments localization. To address the above issues, we propose the Video Similarity and Alignment Learning (VSAL) approach, which jointly models spatial similarity, temporal similarity and partial alignment. To mitigate the spatial similarity bias, we model the temporal similarity as the mask map predicted from frame-level spatial similarity, where each element indicates the probability of frame pair lying right on the partial alignments. To further localize partial copies, the step map is learned from the spatial similarity where the elements indicate extending directions of the current partial alignments on the spatial-temporal similarity map. Obtained from the mask map, the start points extend out into partial optimal alignments following instructions of the step map. With the similarity and alignment learning strategy, VSAL achieves the state-of-the-art F1-score on VCDB core dataset. Furthermore, we construct a new benchmark of partial video copy detection and localization by adding new segment-level annotations for FIVR-200k dataset, where VSAL also achieves the best performance, verifying its effectiveness in more challenging situations. Our project is publicly available at https://pvcd-vsal.github.io/vsal/.