 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Object Segmentation Without Temporal Information
Paper and Code
May 16, 2018
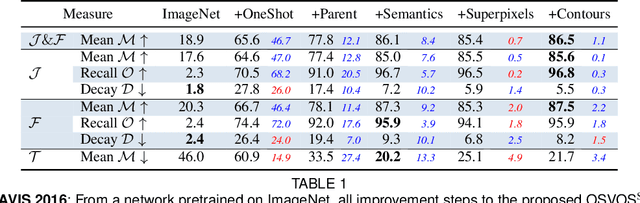
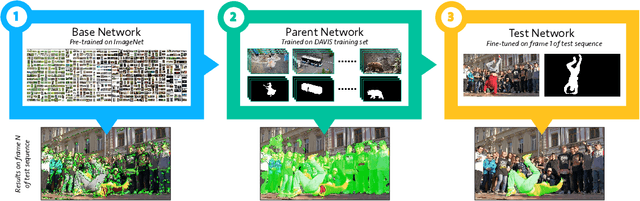
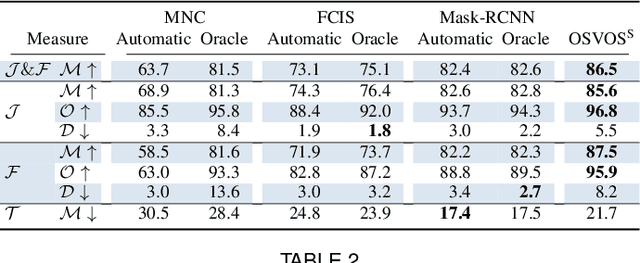
Video Object Segmentation, and video processing in general, has been historically dominated by methods that rely on the temporal consistency and redundancy in consecutive video frames. When the temporal smoothness is suddenly broken, such as when an object is occluded, or some frames are missing in a sequence, the result of these methods can deteriorate significantly or they may not even produce any result at all. This paper explores the orthogonal approach of processing each frame independently, i.e disregarding the temporal information. In particular, it tackles the task of semi-supervised video object segmentation: the separation of an object from the background in a video, given its mask in the first frame. We present Semantic One-Shot Video Object Segmentation (OSVOS-S), based on a fully-convolutional neural network architecture that is able to successively transfer generic semantic information, learned on ImageNet, to the task of foreground segmentation, and finally to learning the appearance of a single annotated object of the test sequence (hence one shot). We show that instance level semantic information, when combined effectively, can dramatically improve the results of our previous method, OSVOS. We perform experiments on two recent video segmentation databases, which show that OSVOS-S is both the fastest and most accurate method in the state of the art.