 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable Planning in Expected Reward Multichain MDPs
Paper and Code
Dec 03, 2020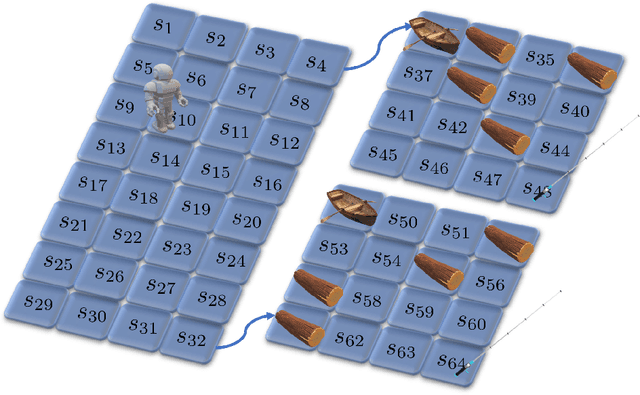
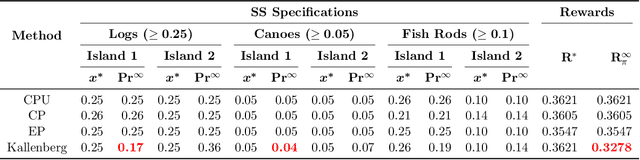
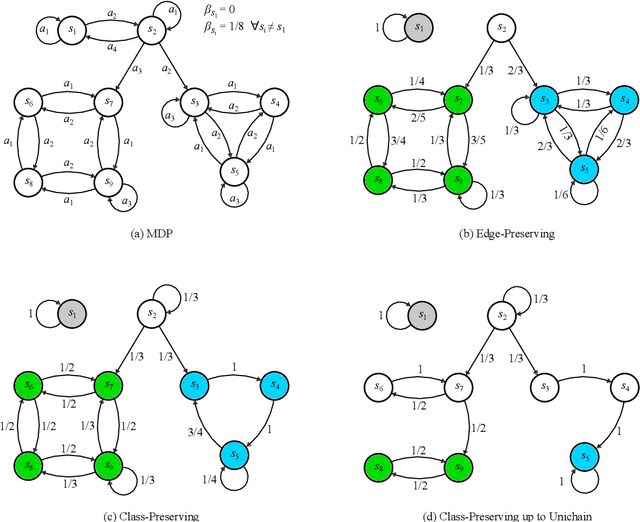
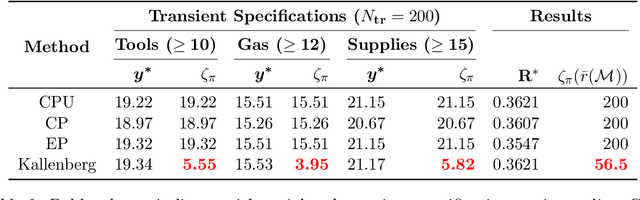
The planning domain has experienced increased interest in the formal synthesis of decision-making policies. This formal synthesis typically entails finding a policy which satisfies formal specifications in the form of some well-defined logic, such as Linear Temporal Logic (LTL) or Computation Tree Logic (CTL), among others. While such logics are very powerful and expressive in their capacity to capture desirable agent behavior, their value is limited when deriving decision-making policies which satisfy certain types of asymptotic behavior. In particular, we are interested in specifying constraints on the steady-state behavior of an agent, which captures the proportion of time an agent spends in each state as it interacts for an indefinite period of time with its environment. This is sometimes called the average or expected behavior of the agent. In this paper, we explore the steady-state planning problem of deriving a decision-making policy for an agent such that constraints on its steady-state behavior are satisfied. A linear programming solution for the general case of multichain Markov Decision Processes (MDPs) is proposed and we prove that optimal solutions to the proposed programs yield stationary policies with rigorous guarantees of behavior.