 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Reducing Couplings for Random Features: Perspectives from Optimal Transport
Paper and Code


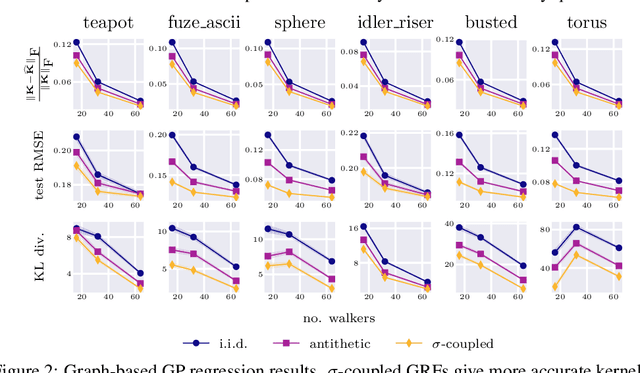

Random features (RFs) are a popular technique to scale up kernel methods in machine learning, replacing exact kernel evaluations with stochastic Monte Carlo estimates. They underpin models as diverse as efficient transformers (by approximating attention) to sparse spectrum Gaussian processes (by approximating the covariance function). Efficiency can be further improved by speeding up the convergence of these estimates: a variance reduction problem. We tackle this through the unifying framework of optimal transport, using theoretical insights and numerical algorithms to develop novel, high-performing RF couplings for kernels defined on Euclidean and discrete input spaces. They enjoy concrete theoretical performance guarantees and sometimes provide strong empirical downstream gains, including for scalable approximate inference on graphs. We reach surprising conclusions about the benefits and limitations of variance reduction as a paradigm.