 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Extraction of Phenotypes from Cancer Clinical Notes for Association Studies
Paper and Code
May 03, 2019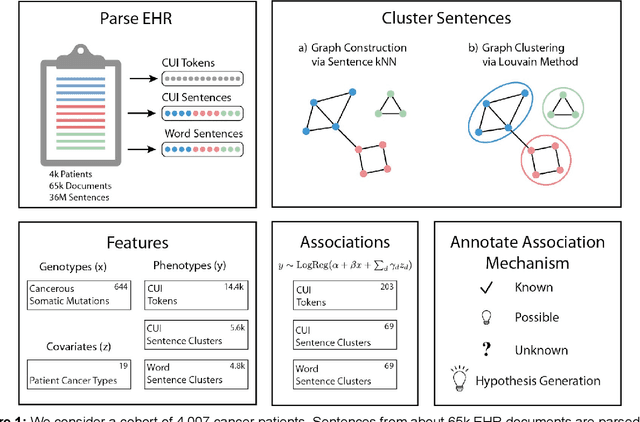
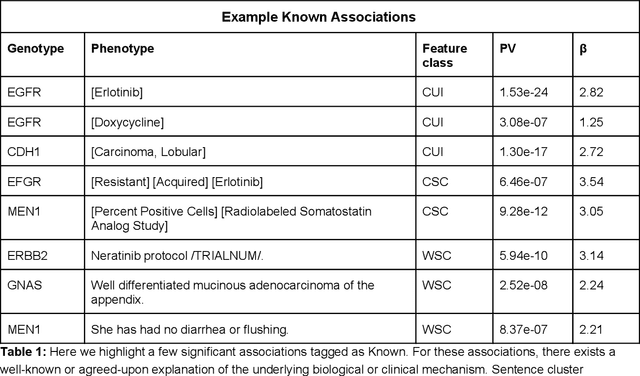
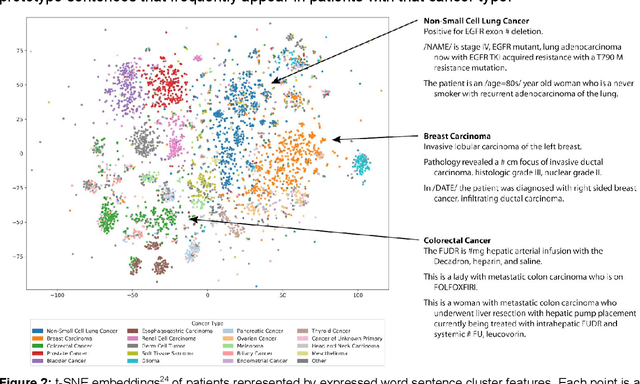
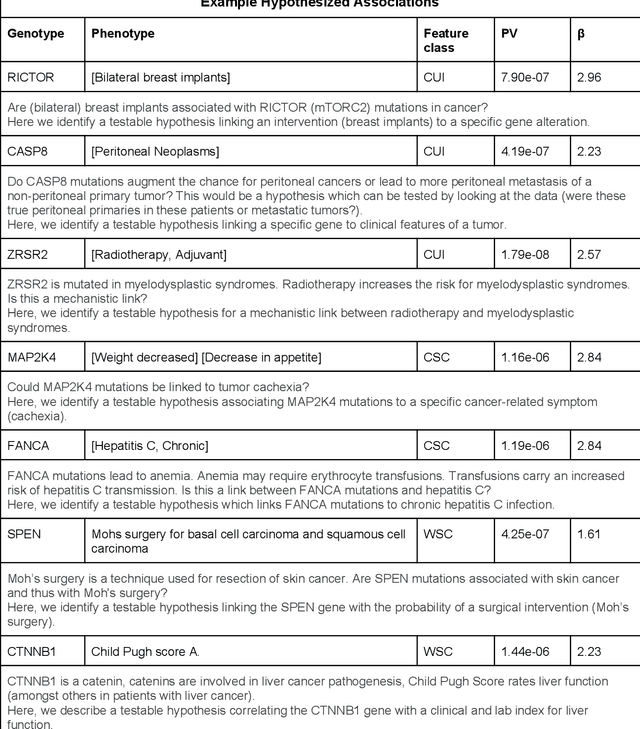
The recent adoption of Electronic Health Records (EHRs) by health care providers has introduced an important source of data that provides detailed and highly specific insights into patient phenotypes over large cohorts. These datasets, in combination with machine learning and statistical approaches, generate new opportunities for research and clinical care. However, many methods require the patient representations to be in structured formats, while the information in the EHR is often locked in unstructured texts designed for human readability. In this work, we develop the methodology to automatically extract clinical features from clinical narratives from large EHR corpora without the need for prior knowledge. We consider medical terms and sentences appearing in clinical narratives as atomic information units. We propose an efficient clustering strategy suitable for the analysis of large text corpora and to utilize the clusters to represent information about the patient compactly. To demonstrate the utility of our approach, we perform an association study of clinical features with somatic mutation profiles from 4,007 cancer patients and their tumors. We apply the proposed algorithm to a dataset consisting of about 65 thousand documents with a total of about 3.2 million sentences. We identify 341 significant statistical associations between the presence of somatic mutations and clinical features. We annotated these associations according to their novelty, and report several known associations. We also propose 32 testable hypotheses where the underlying biological mechanism does not appear to be known but plausible. These results illustrate that the automated discovery of clinical features is possible and the joint analysis of clinical and genetic datasets can generate appealing new hypotheses.