 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptive Fundus Image Segmentation with Few Labeled Source Data
Paper and Code
Oct 10, 2022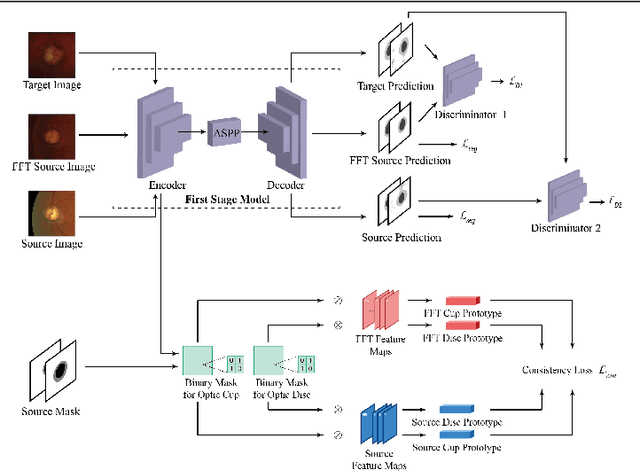
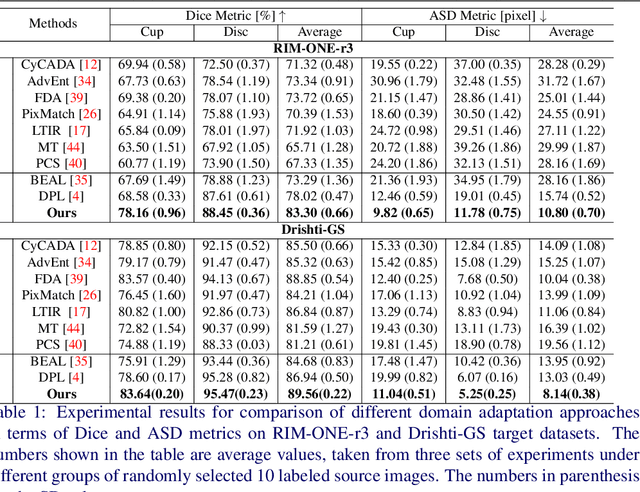
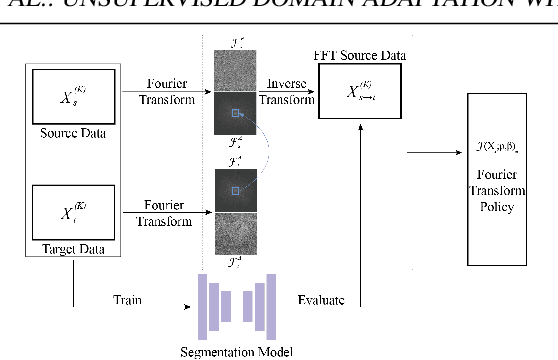
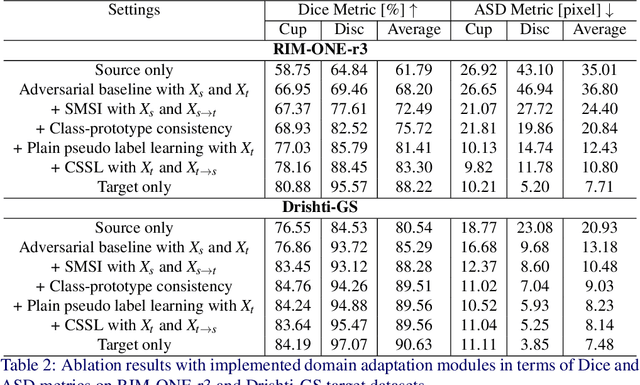
Deep learning-based segmentation methods have been widely employed for automatic glaucoma diagnosis and prognosis. In practice, fundus images obtained by different fundus cameras vary significantly in terms of illumination and intensity. Although recent unsupervised domain adaptation (UDA) methods enhance the models' generalization ability on the unlabeled target fundus datasets, they always require sufficient labeled data from the source domain, bringing auxiliary data acquisition and annotation costs. To further facilitate the data efficiency of the cross-domain segmentation methods on the fundus images, we explore UDA optic disc and cup segmentation problems using few labeled source data in this work. We first design a Searching-based Multi-style Invariant Mechanism to diversify the source data style as well as increase the data amount. Next, a prototype consistency mechanism on the foreground objects is proposed to facilitate the feature alignment for each kind of tissue under different image styles. Moreover, a cross-style self-supervised learning stage is further designed to improve the segmentation performance on the target images. Our method has outperformed several state-of-the-art UDA segmentation methods under the UDA fundus segmentation with few labeled source data.