 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Cross-Modality Retinal Vessel Segmentation via Disentangling Representation Style Transfer and Collaborative Consistency Learning
Paper and Code

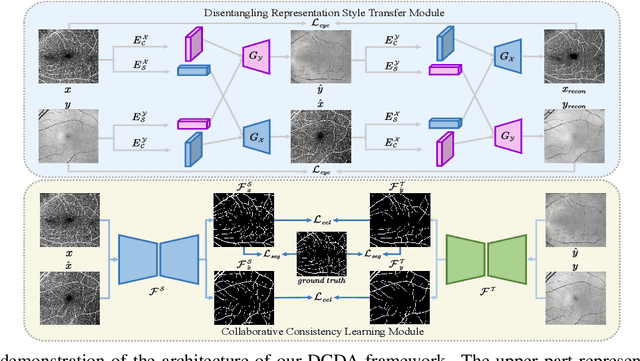


Various deep learning models have been developed to segment anatomical structures from medical images, but they typically have poor performance when tested on another target domain with different data distribution. Recently, unsupervised domain adaptation methods have been proposed to alleviate this so-called domain shift issue, but most of them are designed for scenarios with relatively small domain shifts and are likely to fail when encountering a large domain gap. In this paper, we propose DCDA, a novel cross-modality unsupervised domain adaptation framework for tasks with large domain shifts, e.g., segmenting retinal vessels from OCTA and OCT images. DCDA mainly consists of a disentangling representation style transfer (DRST) module and a collaborative consistency learning (CCL) module. DRST decomposes images into content components and style codes and performs style transfer and image reconstruction. CCL contains two segmentation models, one for source domain and the other for target domain. The two models use labeled data (together with the corresponding transferred images) for supervised learning and perform collaborative consistency learning on unlabeled data. Each model focuses on the corresponding single domain and aims to yield an expertized domain-specific segmentation model. Through extensive experiments on retinal vessel segmentation, our framework achieves Dice scores close to target-trained oracle both from OCTA to OCT and from OCT to OCTA, significantly outperforming other state-of-the-art methods.