Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Data Selection for Supervised Learning
Paper and Code
Oct 29, 2018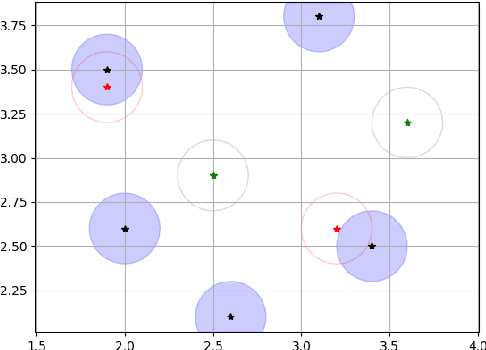
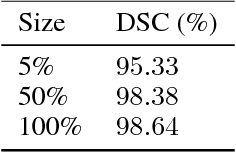
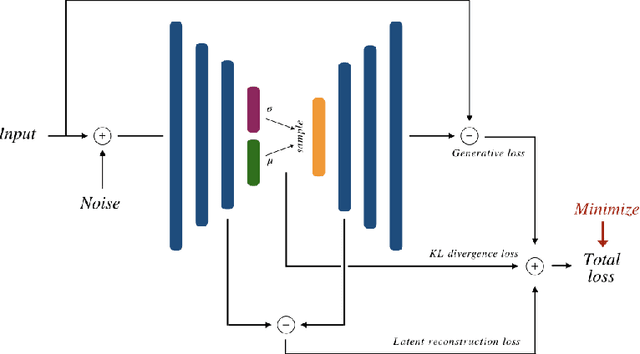
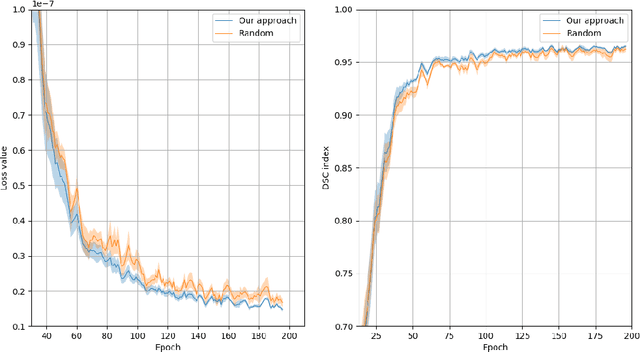
Recent research put a big effort in the development of deep learning architectures and optimizers obtaining impressive results in areas ranging from vision to language processing. However little attention has been addressed to the need of a methodological process of data collection. In this work we show that high quality data for supervised learning can be selected in an unsupervised manner and that by doing so one can obtain models capable to generalize better than in the case of random training set construction.
* Technical Report --- 8 pages, 3 figures
View paper on