 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Vanilla Vision Transformer with Masked Image Modeling for Object Detection
Paper and Code
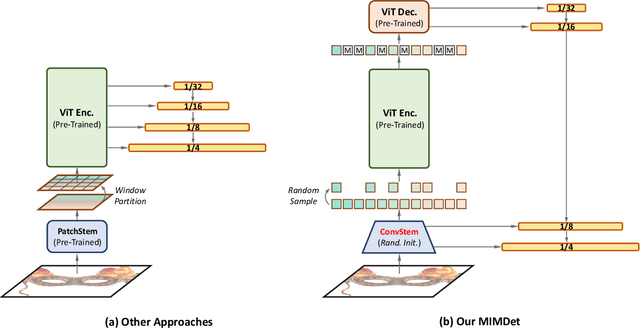
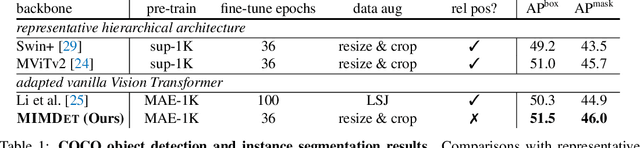
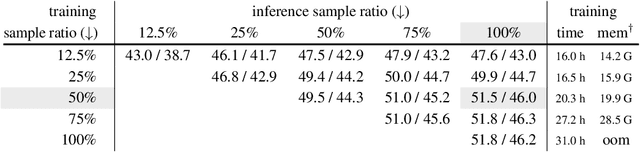

We present an approach to efficiently and effectively adapt a masked image modeling (MIM) pre-trained vanilla Vision Transformer (ViT) for object detection, which is based on our two novel observations: (i) A MIM pre-trained vanilla ViT can work surprisingly well in the challenging object-level recognition scenario even with random sampled partial observations, e.g., only 25% ~ 50% of the input sequence. (ii) In order to construct multi-scale representations for object detection, a random initialized compact convolutional stem supplants the pre-trained large kernel patchify stem, and its intermediate features can naturally serve as the higher resolution inputs of a feature pyramid without upsampling. While the pre-trained ViT is only regarded as the third-stage of our detector's backbone instead of the whole feature extractor, resulting in a ConvNet-ViT hybrid architecture. The proposed detector, named MIMDet, enables a MIM pre-trained vanilla ViT to outperform hierarchical Swin Transformer by 2.3 box AP and 2.5 mask AP on COCO, and achieve even better results compared with other adapted vanilla ViT using a more modest fine-tuning recipe while converging 2.8x faster. Code and pre-trained models are available at \url{https://github.com/hustvl/MIMDet}.