 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlabeled Data Guided Semi-supervised Histopathology Image Segmentation
Paper and Code
Dec 17, 2020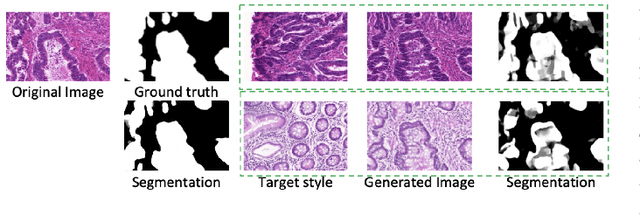


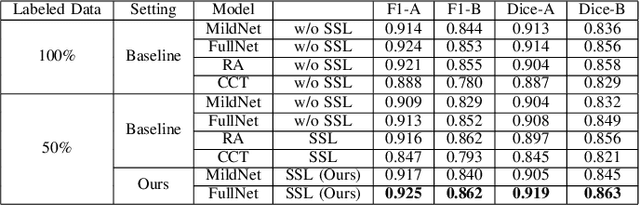
Automatic histopathology image segmentation is crucial to disease analysis. Limited available labeled data hinders the generalizability of trained models under the fully supervised setting. Semi-supervised learning (SSL) based on generative methods has been proven to be effective in utilizing diverse image characteristics. However, it has not been well explored what kinds of generated images would be more useful for model training and how to use such images. In this paper, we propose a new data guided generative method for histopathology image segmentation by leveraging the unlabeled data distributions. First, we design an image generation module. Image content and style are disentangled and embedded in a clustering-friendly space to utilize their distributions. New images are synthesized by sampling and cross-combining contents and styles. Second, we devise an effective data selection policy for judiciously sampling the generated images: (1) to make the generated training set better cover the dataset, the clusters that are underrepresented in the original training set are covered more; (2) to make the training process more effective, we identify and oversample the images of "hard cases" in the data for which annotated training data may be scarce. Our method is evaluated on glands and nuclei datasets. We show that under both the inductive and transductive settings, our SSL method consistently boosts the performance of common segmentation models and attains state-of-the-art results.