 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Approximation Under Constraints is Possible with Transformers
Paper and Code
Oct 07, 2021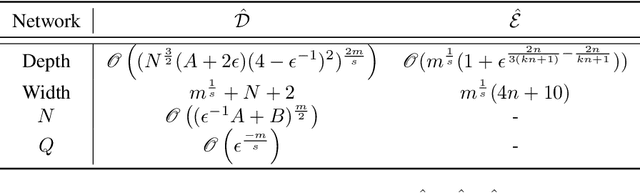

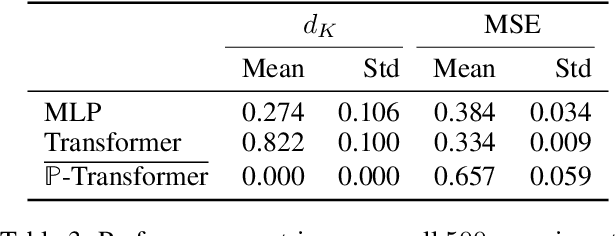
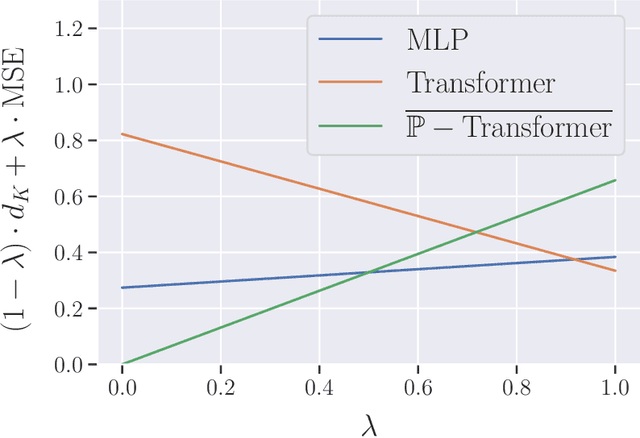
Many practical problems need the output of a machine learning model to satisfy a set of constraints, $K$. Nevertheless, there is no known guarantee that classical neural network architectures can exactly encode constraints while simultaneously achieving universality. We provide a quantitative constrained universal approximation theorem which guarantees that for any non-convex compact set $K$ and any continuous function $f:\mathbb{R}^n\rightarrow K$, there is a probabilistic transformer $\hat{F}$ whose randomized outputs all lie in $K$ and whose expected output uniformly approximates $f$. Our second main result is a "deep neural version" of Berge's Maximum Theorem (1963). The result guarantees that given an objective function $L$, a constraint set $K$, and a family of soft constraint sets, there is a probabilistic transformer $\hat{F}$ that approximately minimizes $L$ and whose outputs belong to $K$; moreover, $\hat{F}$ approximately satisfies the soft constraints. Our results imply the first universal approximation theorem for classical transformers with exact convex constraint satisfaction. They also yield that a chart-free universal approximation theorem for Riemannian manifold-valued functions subject to suitable geodesically convex constraints.