 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Entropic Regularization in GANs
Paper and Code
Nov 02, 2021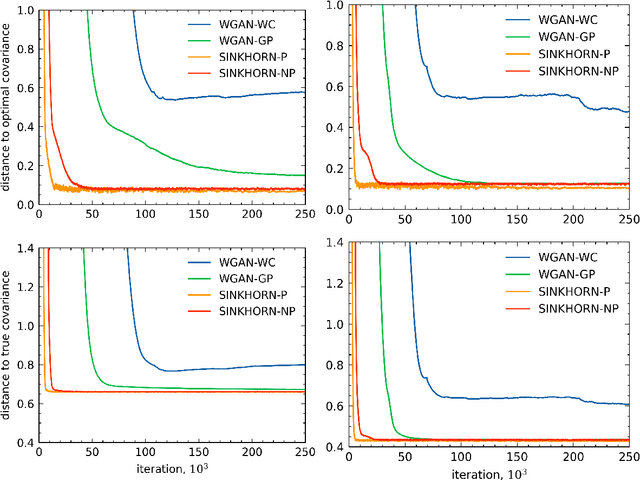
Generative Adversarial Networks are a popular method for learning distributions from data by modeling the target distribution as a function of a known distribution. The function, often referred to as the generator, is optimized to minimize a chosen distance measure between the generated and target distributions. One commonly used measure for this purpose is the Wasserstein distance. However, Wasserstein distance is hard to compute and optimize, and in practice entropic regularization techniques are used to improve numerical convergence. The influence of regularization on the learned solution, however, remains not well-understood. In this paper, we study how several popular entropic regularizations of Wasserstein distance impact the solution in a simple benchmark setting where the generator is linear and the target distribution is high-dimensional Gaussian. We show that entropy regularization promotes the solution sparsification, while replacing the Wasserstein distance with the Sinkhorn divergence recovers the unregularized solution. Both regularization techniques remove the curse of dimensionality suffered by Wasserstein distance. We show that the optimal generator can be learned to accuracy $\epsilon$ with $O(1/\epsilon^2)$ samples from the target distribution. We thus conclude that these regularization techniques can improve the quality of the generator learned from empirical data for a large class of distributions.