 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertain Natural Language Inference
Paper and Code
Sep 06, 2019


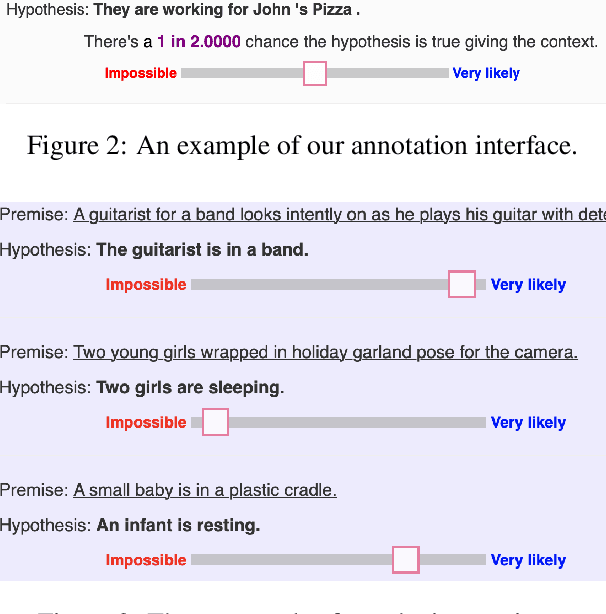
We propose a refinement of Natural Language Inference (NLI), called Uncertain Natural Language Inference (UNLI), that shifts away from categorical labels, targeting instead the direct prediction of subjective probability assessments. Chiefly, we demonstrate the feasibility of collecting annotations for UNLI by relabeling a portion of the SNLI dataset under a psychologically motivated probabilistic scale, where items even with the same categorical label, e.g., "contradictions" differ in how likely people judge them to be strictly impossible given a premise. We describe two modeling approaches, as direct scalar regression and as learning-to-rank, finding that existing categorically labeled NLI data can be used in pre-training. Our best models correlate well with humans, demonstrating models are capable of more subtle inferences than the ternary bin assignment employed in current NLI tasks.