 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO: A UniFied TransfOrmer for Vision-Language Representation Learning
Paper and Code
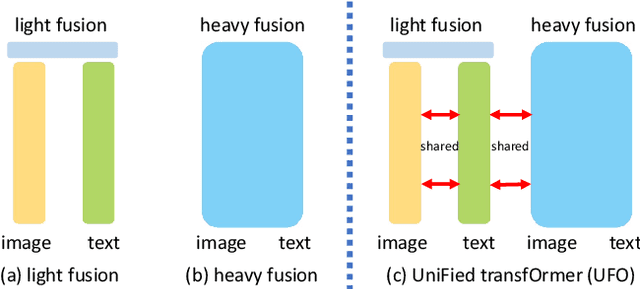
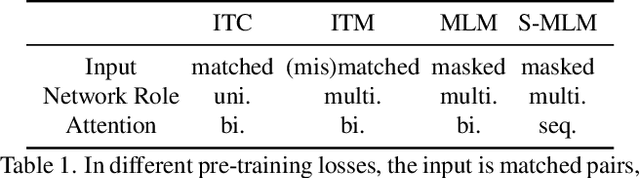

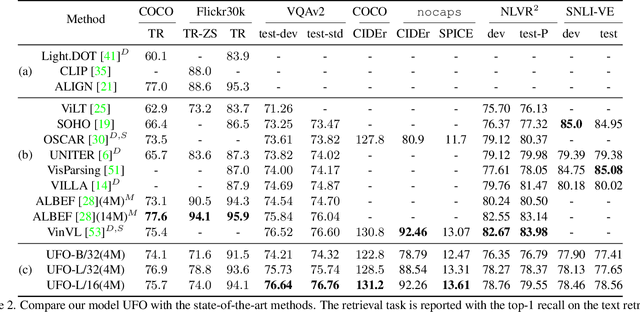
In this paper, we propose a single UniFied transfOrmer (UFO), which is capable of processing either unimodal inputs (e.g., image or language) or multimodal inputs (e.g., the concatenation of the image and the question), for vision-language (VL) representation learning. Existing approaches typically design an individual network for each modality and/or a specific fusion network for multimodal tasks. To simplify the network architecture, we use a single transformer network and enforce multi-task learning during VL pre-training, which includes the image-text contrastive loss, image-text matching loss, and masked language modeling loss based on the bidirectional and the seq2seq attention mask. The same transformer network is used as the image encoder, the text encoder, or the fusion network in different pre-training tasks. Empirically, we observe less conflict among different tasks and achieve new state of the arts on visual question answering, COCO image captioning (cross-entropy optimization) and nocaps (in SPICE). On other downstream tasks, e.g., image-text retrieval, we also achieve competitive performance.