 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Fine-Tuning: A Novel Strategy for Learning Class-Imbalanced Data
Paper and Code

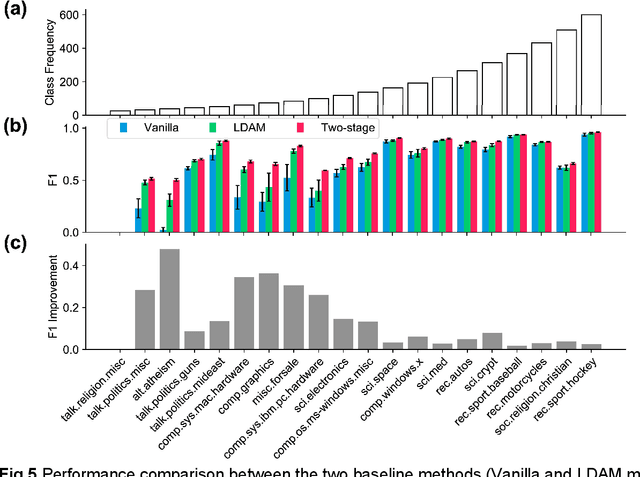
Classification on long-tailed distributed data is a challenging problem, which suffers from serious class-imbalance and hence poor performance on tail classes with only a few samples. Owing to this paucity of samples, learning on the tail classes is especially challenging for the fine-tuning when transferring a pretrained model to a downstream task. In this work, we present a simple modification of standard fine-tuning to cope with these challenges. Specifically, we propose a two-stage fine-tuning: we first fine-tune the final layer of the pretrained model with class-balanced reweighting loss, and then we perform the standard fine-tuning. Our modification has several benefits: (1) it leverages pretrained representations by only fine-tuning a small portion of the model parameters while keeping the rest untouched; (2) it allows the model to learn an initial representation of the specific task; and importantly (3) it protects the learning of tail classes from being at a disadvantage during the model updating. We conduct extensive experiments on synthetic datasets of both two-class and multi-class tasks of text classification as well as a real-world application to ADME (i.e., absorption, distribution, metabolism, and excretion) semantic labeling. The experimental results show that the proposed two-stage fine-tuning outperforms both fine-tuning with conventional loss and fine-tuning with a reweighting loss on the above datasets.