 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn-Taking Prediction for Natural Conversational Speech
Paper and Code
Aug 29, 2022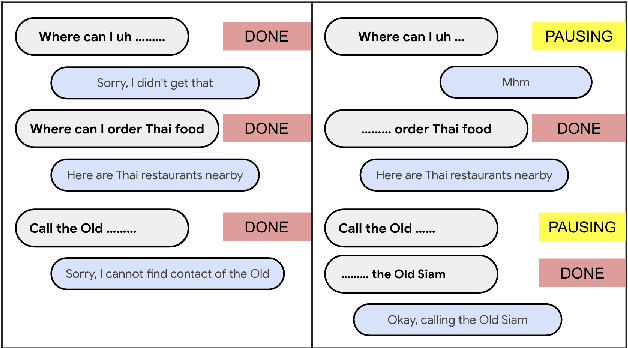
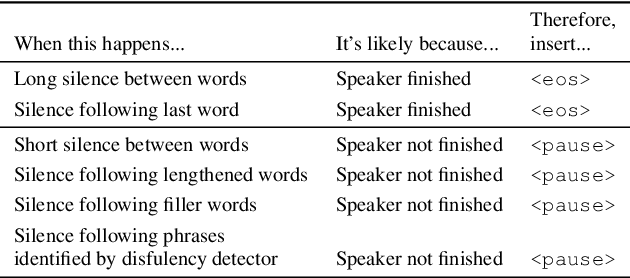
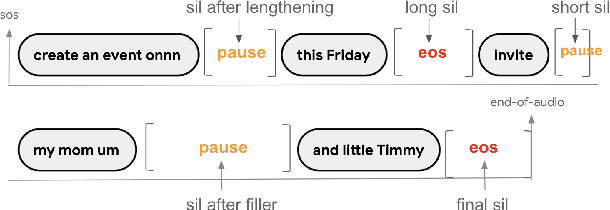
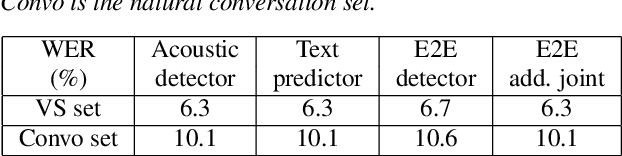
While a streaming voice assistant system has been used in many applications, this system typically focuses on unnatural, one-shot interactions assuming input from a single voice query without hesitation or disfluency. However, a common conversational utterance often involves multiple queries with turn-taking, in addition to disfluencies. These disfluencies include pausing to think, hesitations, word lengthening, filled pauses and repeated phrases. This makes doing speech recognition with conversational speech, including one with multiple queries, a challenging task. To better model the conversational interaction, it is critical to discriminate disfluencies and end of query in order to allow the user to hold the floor for disfluencies while having the system respond as quickly as possible when the user has finished speaking. In this paper, we present a turntaking predictor built on top of the end-to-end (E2E) speech recognizer. Our best system is obtained by jointly optimizing for ASR task and detecting when the user is paused to think or finished speaking. The proposed approach demonstrates over 97% recall rate and 85% precision rate on predicting true turn-taking with only 100 ms latency on a test set designed with 4 types of disfluencies inserted in conversational utterances.