Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuplemax Loss for Language Identification
Paper and Code
Nov 29, 2018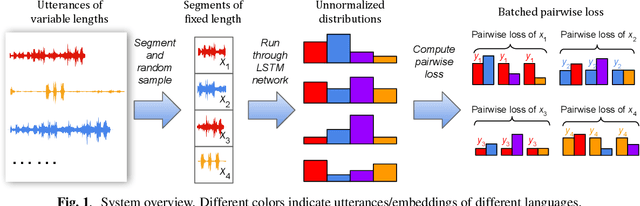

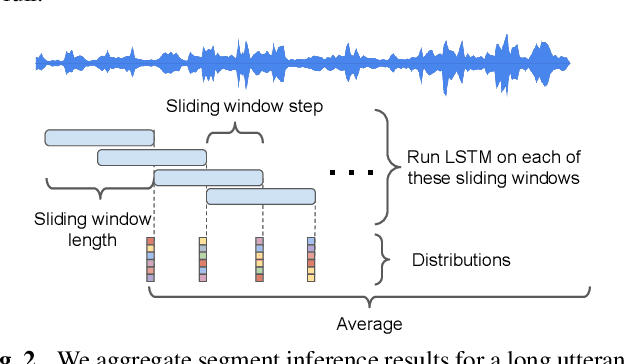
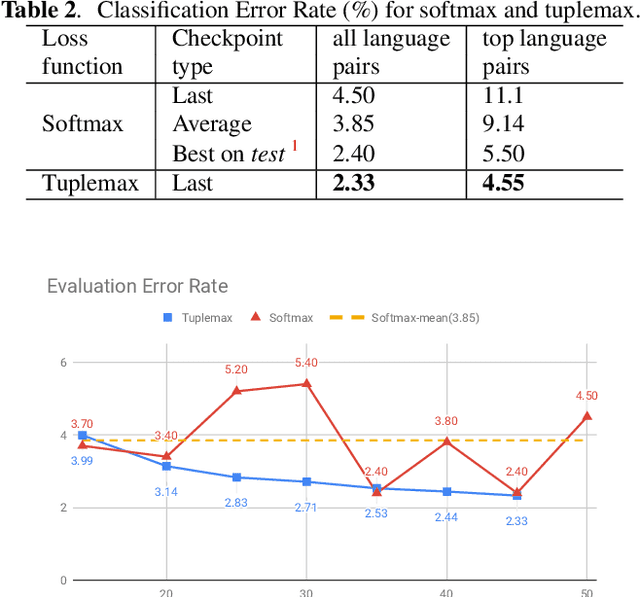
In many scenarios of a language identification task, the user will specify a small set of languages which he/she can speak instead of a large set of all possible languages. We want to model such prior knowledge into the way we train our neural networks, by replacing the commonly used softmax loss function with a novel loss function named tuplemax loss. As a matter of fact, a typical language identification system launched in North America has about 95% users who could speak no more than two languages. Using the tuplemax loss, our system achieved a 2.33% error rate, which is a relative 39.4% improvement over the 3.85% error rate of standard softmax loss method.
* Submitted to ICASSP 2019
View paper on