 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Region-Guided Proximal Policy Optimization
Paper and Code
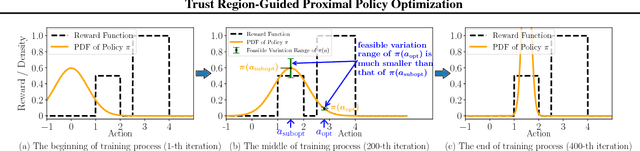
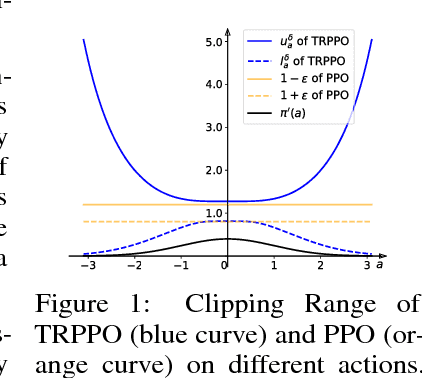
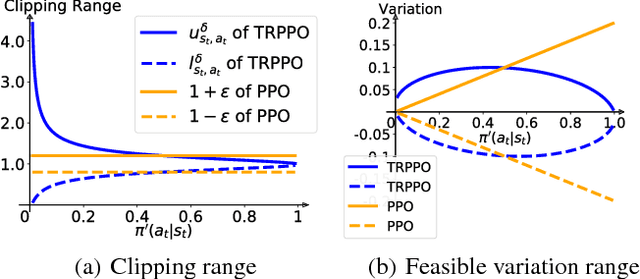
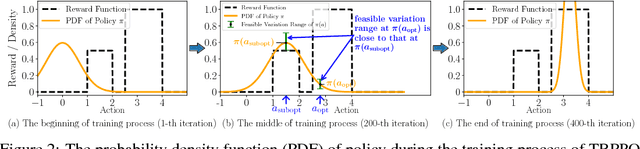
Model-free reinforcement learning relies heavily on a safe yet exploratory policy search. Proximal policy optimization (PPO) is a prominent algorithm to address the safe search problem, by exploiting a heuristic clipping mechanism motivated by a theoretically-justified "trust region" guidance. However, we found that the clipping mechanism of PPO could lead to a lack of exploration issue. Based on this finding, we improve the original PPO with an adaptive clipping mechanism guided by a "trust region" criterion. Our method, termed as Trust Region-Guided PPO (TRPPO), improves PPO with more exploration and better sample efficiency, while maintains the safe search property and design simplicity of PPO. On several benchmark tasks, TRPPO significantly outperforms the original PPO and is competitive with several state-of-the-art methods.