 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransVG++: End-to-End Visual Grounding with Language Conditioned Vision Transformer
Paper and Code
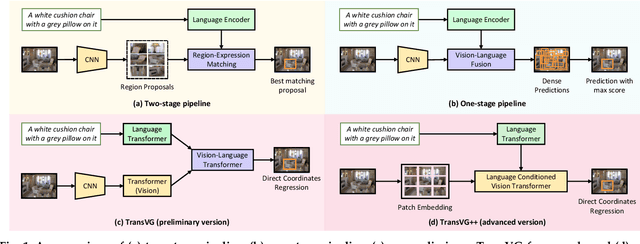


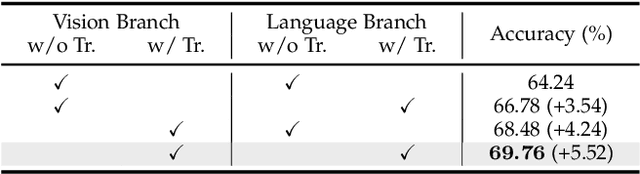
In this work, we explore neat yet effective Transformer-based frameworks for visual grounding. The previous methods generally address the core problem of visual grounding, i.e., multi-modal fusion and reasoning, with manually-designed mechanisms. Such heuristic designs are not only complicated but also make models easily overfit specific data distributions. To avoid this, we first propose TransVG, which establishes multi-modal correspondences by Transformers and localizes referred regions by directly regressing box coordinates. We empirically show that complicated fusion modules can be replaced by a simple stack of Transformer encoder layers with higher performance. However, the core fusion Transformer in TransVG is stand-alone against uni-modal encoders, and thus should be trained from scratch on limited visual grounding data, which makes it hard to be optimized and leads to sub-optimal performance. To this end, we further introduce TransVG++ to make two-fold improvements. For one thing, we upgrade our framework to a purely Transformer-based one by leveraging Vision Transformer (ViT) for vision feature encoding. For another, we devise Language Conditioned Vision Transformer that removes external fusion modules and reuses the uni-modal ViT for vision-language fusion at the intermediate layers. We conduct extensive experiments on five prevalent datasets, and report a series of state-of-the-art records.