 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparent Model Distillation
Paper and Code

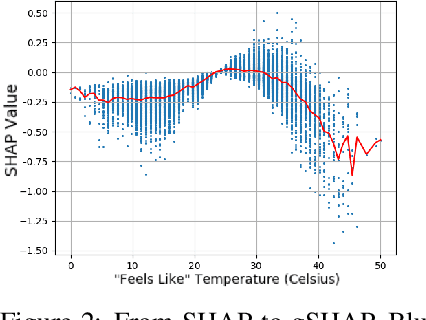

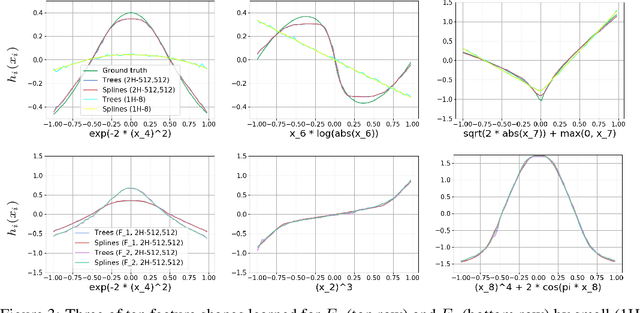
Model distillation was originally designed to distill knowledge from a large, complex teacher model to a faster, simpler student model without significant loss in prediction accuracy. We investigate model distillation for another goal -- transparency -- investigating if fully-connected neural networks can be distilled into models that are transparent or interpretable in some sense. Our teacher models are multilayer perceptrons, and we try two types of student models: (1) tree-based generalized additive models (GA2Ms), a type of boosted, short tree (2) gradient boosted trees (GBTs). More transparent student models are forthcoming. Our results are not yet conclusive. GA2Ms show some promise for distilling binary classification teachers, but not yet regression. GBTs are not "directly" interpretable but may be promising for regression teachers. GA2M models may provide a computationally viable alternative to additive decomposition methods for global function approximation.