 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrainability of Dissipative Perceptron-Based Quantum Neural Networks
Paper and Code
May 26, 2020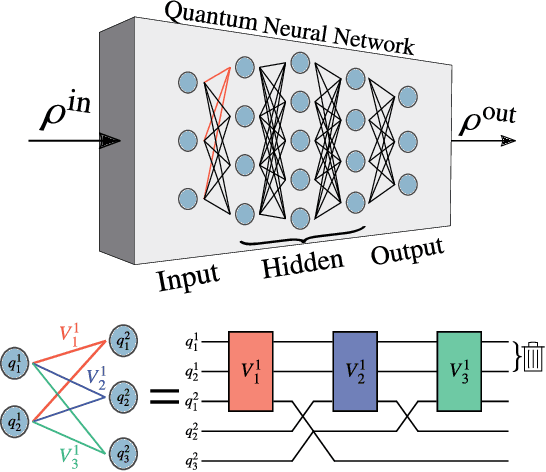
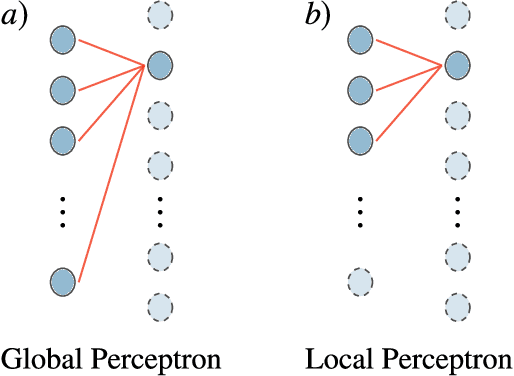

Several architectures have been proposed for quantum neural networks (QNNs), with the goal of efficiently performing machine learning tasks on quantum data. Rigorous scaling results are urgently needed for specific QNN constructions to understand which, if any, will be trainable at a large scale. Here, we analyze the gradient scaling (and hence the trainability) for a recently proposed architecture that we called dissipative QNNs (DQNNs), where the input qubits of each layer are discarded at the layer's output. We find that DQNNs can exhibit barren plateaus, i.e., gradients that vanish exponentially in the number of qubits. Moreover, we provide quantitative bounds on the scaling of the gradient for DQNNs under different conditions, such as different cost functions and circuit depths, and show that trainability is not always guaranteed.