 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrading-off variance and complexity in stochastic gradient descent
Paper and Code
Mar 22, 2016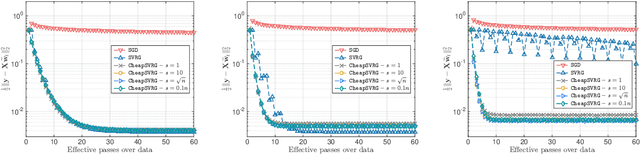

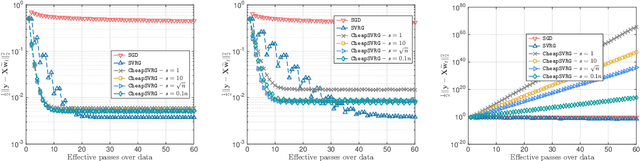

Stochastic gradient descent is the method of choice for large-scale machine learning problems, by virtue of its light complexity per iteration. However, it lags behind its non-stochastic counterparts with respect to the convergence rate, due to high variance introduced by the stochastic updates. The popular Stochastic Variance-Reduced Gradient (SVRG) method mitigates this shortcoming, introducing a new update rule which requires infrequent passes over the entire input dataset to compute the full-gradient. In this work, we propose CheapSVRG, a stochastic variance-reduction optimization scheme. Our algorithm is similar to SVRG but instead of the full gradient, it uses a surrogate which can be efficiently computed on a small subset of the input data. It achieves a linear convergence rate ---up to some error level, depending on the nature of the optimization problem---and features a trade-off between the computational complexity and the convergence rate. Empirical evaluation shows that CheapSVRG performs at least competitively compared to the state of the art.