 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrading Convergence Rate with Computational Budget in High Dimensional Bayesian Optimization
Paper and Code
Nov 27, 2019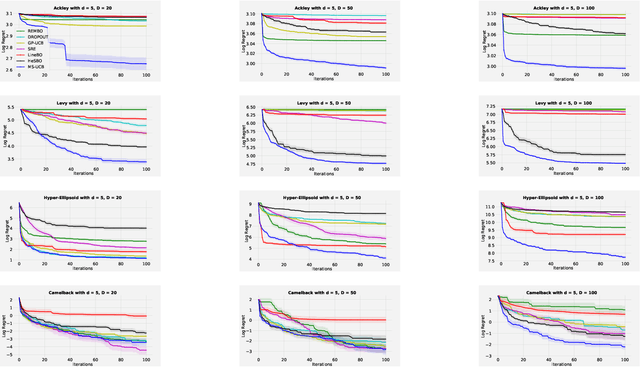
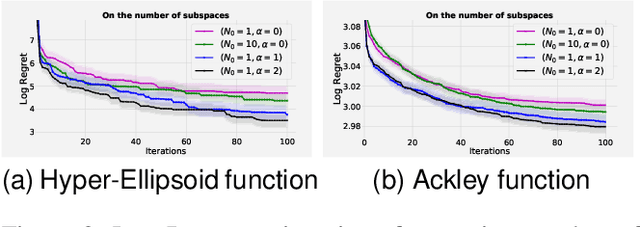
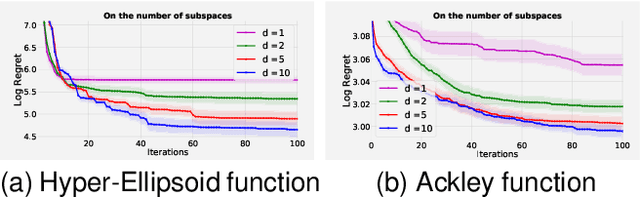

Scaling Bayesian optimisation (BO) to high-dimensional search spaces is a active and open research problems particularly when no assumptions are made on function structure. The main reason is that at each iteration, BO requires to find global maximisation of acquisition function, which itself is a non-convex optimization problem in the original search space. With growing dimensions, the computational budget for this maximisation gets increasingly short leading to inaccurate solution of the maximisation. This inaccuracy adversely affects both the convergence and the efficiency of BO. We propose a novel approach where the acquisition function only requires maximisation on a discrete set of low dimensional subspaces embedded in the original high-dimensional search space. Our method is free of any low dimensional structure assumption on the function unlike many recent high-dimensional BO methods. Optimising acquisition function in low dimensional subspaces allows our method to obtain accurate solutions within limited computational budget. We show that in spite of this convenience, our algorithm remains convergent. In particular, cumulative regret of our algorithm only grows sub-linearly with the number of iterations. More importantly, as evident from our regret bounds, our algorithm provides a way to trade the convergence rate with the number of subspaces used in the optimisation. Finally, when the number of subspaces is "sufficiently large", our algorithm's cumulative regret is at most $\mathcal{O}^{*}(\sqrt{T\gamma_T})$ as opposed to $\mathcal{O}^{*}(\sqrt{DT\gamma_T})$ for the GP-UCB of Srinivas et al. (2012), reducing a crucial factor $\sqrt{D}$ where $D$ being the dimensional number of input space.