 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Task Embeddings Across Multiple Models: Bridging the Gap for Prompt-Based Large Language Models and Beyond
Paper and Code
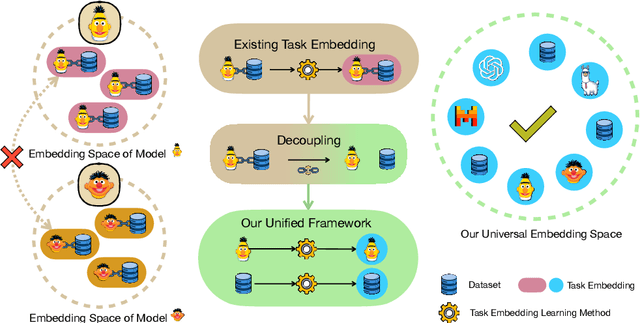
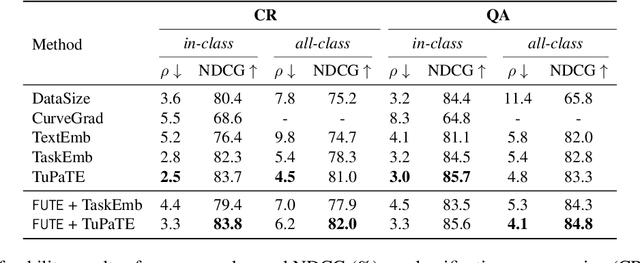
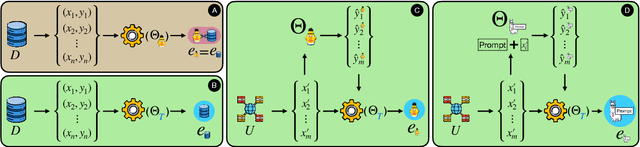
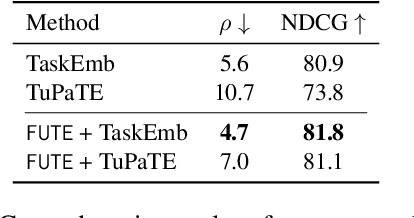
Task embedding, a meta-learning technique that captures task-specific information, has become prevalent, especially in areas such as multi-task learning, model editing, and interpretability. However, it faces challenges with the emergence of prompt-guided Large Language Models (LLMs) operating in a gradientfree manner. Existing task embedding methods rely on fine-tuned, task-specific language models, which hinders the adaptability of task embeddings across diverse models, especially prompt-based LLMs. To unleash the power of task embedding in the era of LLMs, we propose a framework for unified task embeddings (FUTE), harmonizing task embeddings from various models, including smaller language models and LLMs with varied prompts, within a single vector space. Such uniformity enables the comparison and analysis of similarities amongst different models, extending the scope and utility of existing task embedding methods in addressing multi-model scenarios, whilst maintaining their performance to be comparable to architecture-specific methods.