 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Feature Learning in Out-of-Distribution Generalization
Paper and Code



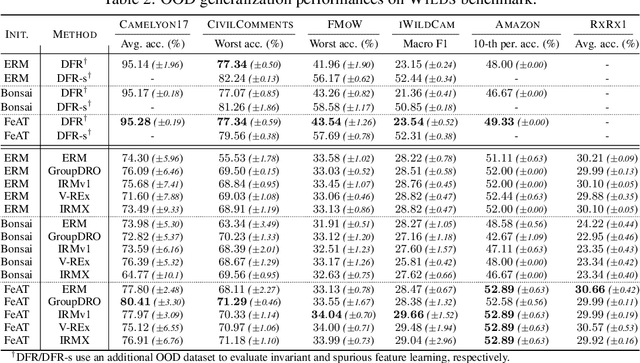
A common explanation for the failure of out-of-distribution (OOD) generalization is that the model trained with empirical risk minimization (ERM) learns spurious features instead of the desired invariant features. However, several recent studies challenged this explanation and found that deep networks may have already learned sufficiently good features for OOD generalization. The debate extends to the in-distribution and OOD performance correlations along with training or fine-tuning neural nets across a variety of OOD generalization tasks. To understand these seemingly contradicting phenomena, we conduct a theoretical investigation and find that ERM essentially learns both spurious features and invariant features. On the other hand, the quality of learned features during ERM pre-training significantly affects the final OOD performance, as OOD objectives rarely learn new features. Failing to capture all the underlying useful features during pre-training will further limit the final OOD performance. To remedy the issue, we propose Feature Augmented Training (FAT ), to enforce the model to learn all useful features by retaining the already learned features and augmenting new ones by multiple rounds. In each round, the retention and augmentation operations are performed on different subsets of the training data that capture distinct features. Extensive experiments show that FAT effectively learns richer features and consistently improves the OOD performance when applied to various objectives.