 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Neural Retrieval Models with Synthetic Pre-Training
Paper and Code
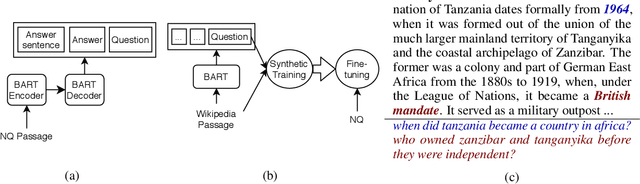

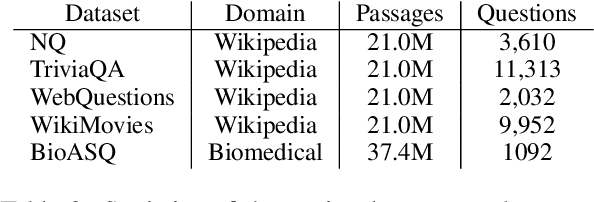

Recent work has shown that commonly available machine reading comprehension (MRC) datasets can be used to train high-performance neural information retrieval (IR) systems. However, the evaluation of neural IR has so far been limited to standard supervised learning settings, where they have outperformed traditional term matching baselines. We conduct in-domain and out-of-domain evaluations of neural IR, and seek to improve its robustness across different scenarios, including zero-shot settings. We show that synthetic training examples generated using a sequence-to-sequence generator can be effective towards this goal: in our experiments, pre-training with synthetic examples improves retrieval performance in both in-domain and out-of-domain evaluation on five different test sets.