 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fully 8-bit Integer Inference for the Transformer Model
Paper and Code
Sep 18, 2020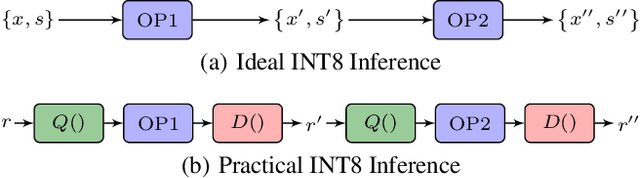



8-bit integer inference, as a promising direction in reducing both the latency and storage of deep neural networks, has made great progress recently. On the other hand, previous systems still rely on 32-bit floating point for certain functions in complex models (e.g., Softmax in Transformer), and make heavy use of quantization and de-quantization. In this work, we show that after a principled modification on the Transformer architecture, dubbed Integer Transformer, an (almost) fully 8-bit integer inference algorithm Scale Propagation could be derived. De-quantization is adopted when necessary, which makes the network more efficient. Our experiments on WMT16 En<->Ro, WMT14 En<->De and En->Fr translation tasks as well as the WikiText-103 language modelling task show that the fully 8-bit Transformer system achieves comparable performance with the floating point baseline but requires nearly 4x less memory footprint.