 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Post-training Quantization of Pre-trained Language Models
Paper and Code

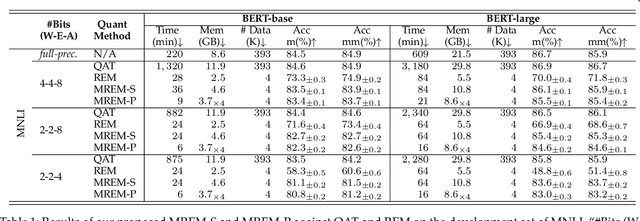


Network quantization has gained increasing attention with the rapid growth of large pre-trained language models~(PLMs). However, most existing quantization methods for PLMs follow quantization-aware training~(QAT) that requires end-to-end training with full access to the entire dataset. Therefore, they suffer from slow training, large memory overhead, and data security issues. In this paper, we study post-training quantization~(PTQ) of PLMs, and propose module-wise quantization error minimization~(MREM), an efficient solution to mitigate these issues. By partitioning the PLM into multiple modules, we minimize the reconstruction error incurred by quantization for each module. In addition, we design a new model parallel training strategy such that each module can be trained locally on separate computing devices without waiting for preceding modules, which brings nearly the theoretical training speed-up (e.g., $4\times$ on $4$ GPUs). Experiments on GLUE and SQuAD benchmarks show that our proposed PTQ solution not only performs close to QAT, but also enjoys significant reductions in training time, memory overhead, and data consumption.