 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Complex Document Understanding By Discrete Reasoning
Paper and Code



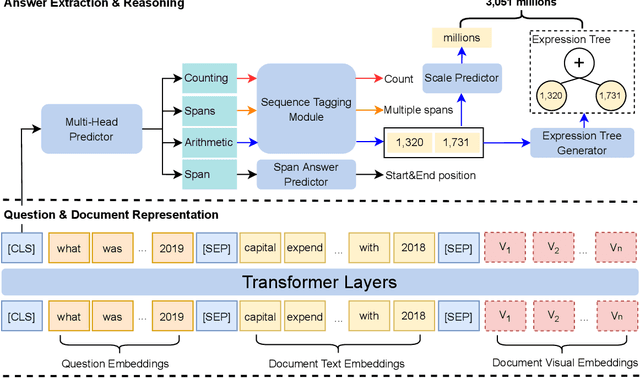
Document Visual Question Answering (VQA) aims to understand visually-rich documents to answer questions in natural language, which is an emerging research topic for both Natural Language Processing and Computer Vision. In this work, we introduce a new Document VQA dataset, named TAT-DQA, which consists of 3,067 document pages comprising semi-structured table(s) and unstructured text as well as 16,558 question-answer pairs by extending the TAT-QA dataset. These documents are sampled from real-world financial reports and contain lots of numbers, which means discrete reasoning capability is demanded to answer questions on this dataset. Based on TAT-DQA, we further develop a novel model named MHST that takes into account the information in multi-modalities, including text, layout and visual image, to intelligently address different types of questions with corresponding strategies, i.e., extraction or reasoning. Extensive experiments show that the MHST model significantly outperforms the baseline methods, demonstrating its effectiveness. However, the performance still lags far behind that of expert humans. We expect that our new TAT-DQA dataset would facilitate the research on deep understanding of visually-rich documents combining vision and language, especially for scenarios that require discrete reasoning. Also, we hope the proposed model would inspire researchers to design more advanced Document VQA models in future.