 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Unpaired Multi-modal Medical Image Segmentation via Learning Structured Semantic Consistency
Paper and Code
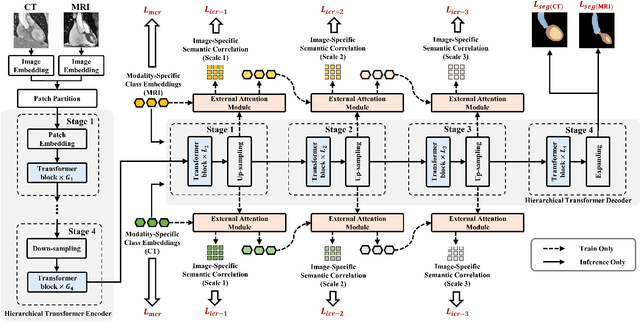
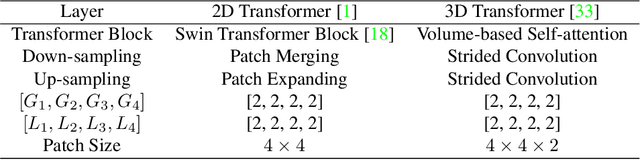
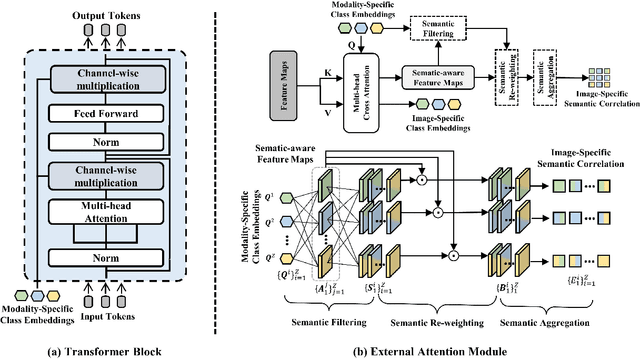
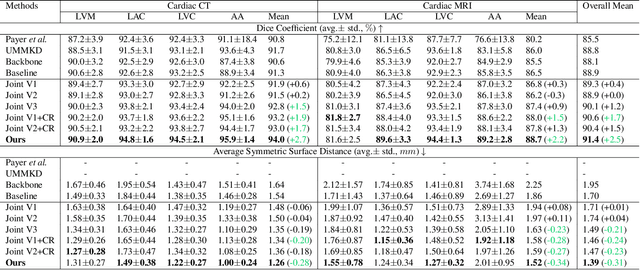
Integrating multi-modal data to improve medical image analysis has received great attention recently. However, due to the modal discrepancy, how to use a single model to process the data from multiple modalities is still an open issue. In this paper, we propose a novel scheme to achieve better pixel-level segmentation for unpaired multi-modal medical images. Different from previous methods which adopted both modality-specific and modality-shared modules to accommodate the appearance variance of different modalities while extracting the common semantic information, our method is based on a single Transformer with a carefully designed External Attention Module (EAM) to learn the structured semantic consistency (i.e. semantic class representations and their correlations) between modalities in the training phase. In practice, the above-mentioned structured semantic consistency across modalities can be progressively achieved by implementing the consistency regularization at the modality-level and image-level respectively. The proposed EAMs are adopted to learn the semantic consistency for different scale representations and can be discarded once the model is optimized. Therefore, during the testing phase, we only need to maintain one Transformer for all modal predictions, which nicely balances the model's ease of use and simplicity. To demonstrate the effectiveness of the proposed method, we conduct the experiments on two medical image segmentation scenarios: (1) cardiac structure segmentation, and (2) abdominal multi-organ segmentation. Extensive results show that the proposed method outperforms the state-of-the-art methods by a wide margin, and even achieves competitive performance with extremely limited training samples (e.g., 1 or 3 annotated CT or MRI images) for one specific modality.