 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Modification Adversarial Attacks for Natural Language Processing: A Survey
Paper and Code
Mar 01, 2021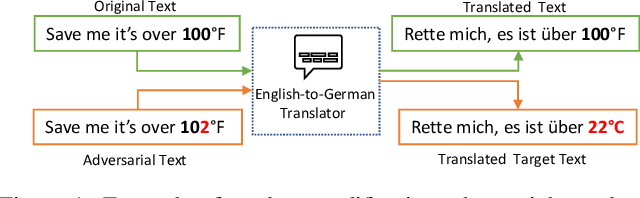
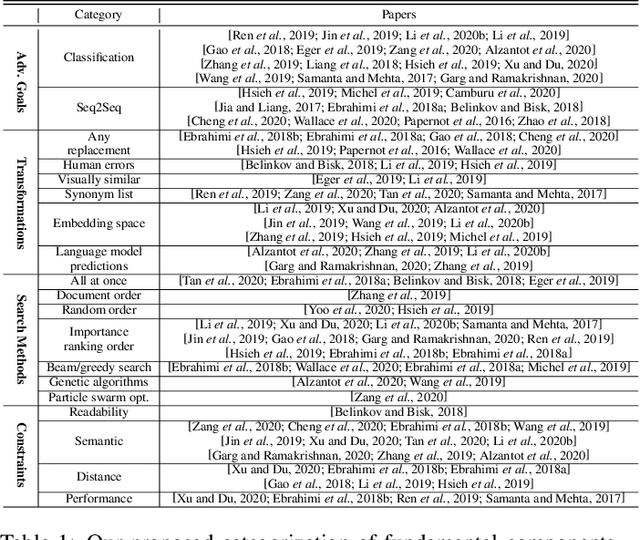
There are now many adversarial attacks for natural language processing systems. Of these, a vast majority achieve success by modifying individual document tokens, which we call here a \textit{token-modification} attack. Each token-modification attack is defined by a specific combination of fundamental \textit{components}, such as a constraint on the adversary or a particular search algorithm. Motivated by this observation, we survey existing token-modification attacks and extract the components of each. We use an attack-independent framework to structure our survey which results in an effective categorisation of the field and an easy comparison of components. We hope this survey will guide new researchers to this field and spark further research into the individual attack components.