 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTighter Expected Generalization Error Bounds via Convexity of Information Measures
Paper and Code
Feb 24, 2022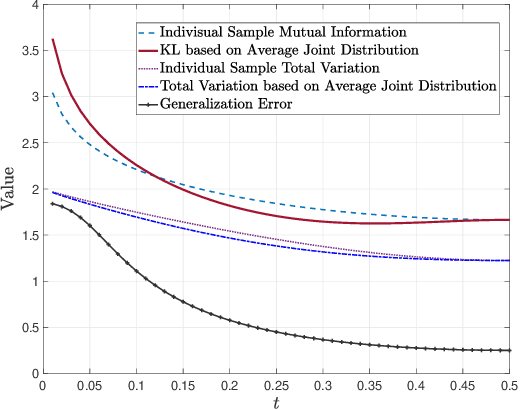
Generalization error bounds are essential to understanding machine learning algorithms. This paper presents novel expected generalization error upper bounds based on the average joint distribution between the output hypothesis and each input training sample. Multiple generalization error upper bounds based on different information measures are provided, including Wasserstein distance, total variation distance, KL divergence, and Jensen-Shannon divergence. Due to the convexity of the information measures, the proposed bounds in terms of Wasserstein distance and total variation distance are shown to be tighter than their counterparts based on individual samples in the literature. An example is provided to demonstrate the tightness of the proposed generalization error bounds.