Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Dimensional MR Image Synthesis with Progressive Generative Adversarial Networks
Paper and Code
Dec 18, 2020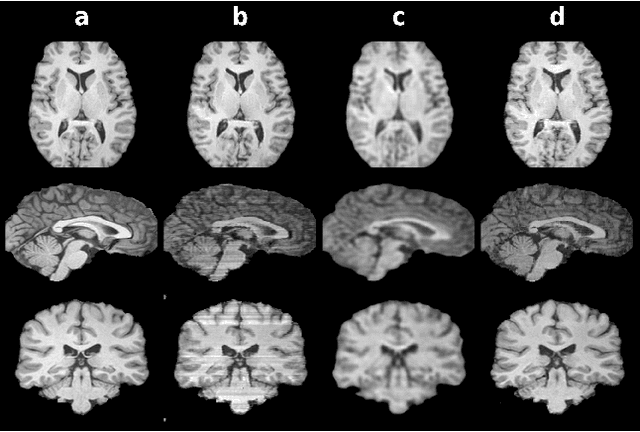
Mainstream deep models for three-dimensional MRI synthesis are either cross-sectional or volumetric depending on the input. Cross-sectional models can decrease the model complexity, but they may lead to discontinuity artifacts. On the other hand, volumetric models can alleviate the discontinuity artifacts, but they might suffer from loss of spatial resolution due to increased model complexity coupled with scarce training data. To mitigate the limitations of both approaches, we propose a novel model that progressively recovers the target volume via simpler synthesis tasks across individual orientations.
* Presented on April 4, 2020 in the IEEE International Symposium on
Biomedical Imaging (ISBI) 2020
View paper on