Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Batch Learning in Stochastic Bandits
Paper and Code
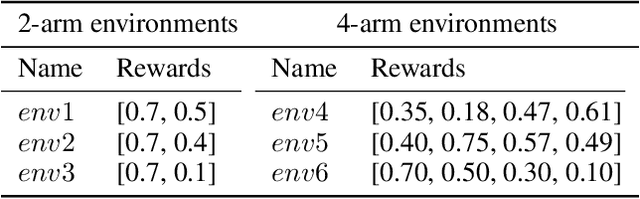
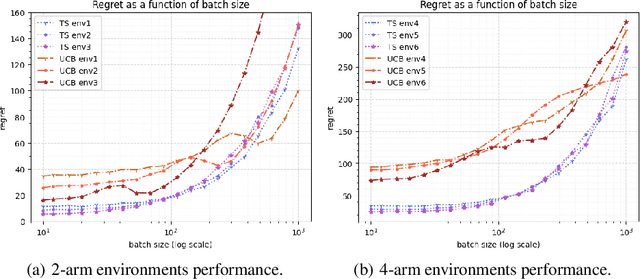
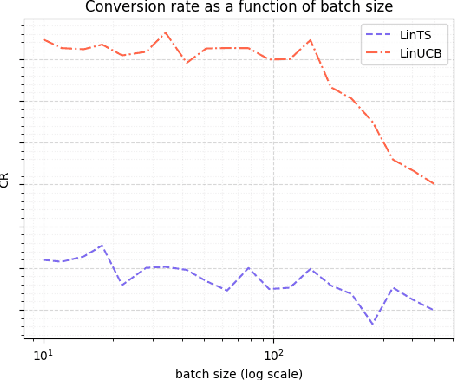
We consider a special case of bandit problems, namely batched bandits. Motivated by natural restrictions of recommender systems and e-commerce platforms, we assume that a learning agent observes responses batched in groups over a certain time period. Unlike previous work, we consider a more practically relevant batch-centric scenario of batch learning. We provide a policy-agnostic regret analysis and demonstrate upper and lower bounds for the regret of a candidate policy. Our main theoretical results show that the impact of batch learning can be measured in terms of online behavior. Finally, we demonstrate the consistency of theoretical results by conducting empirical experiments and reflect on the optimal batch size choice.
* To appear at the workshop on the Ecological Theory of Reinforcement
Learning, NeurIPS 2021
View paper on