 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Generalization-Stability Tradeoff in Neural Network Pruning
Paper and Code
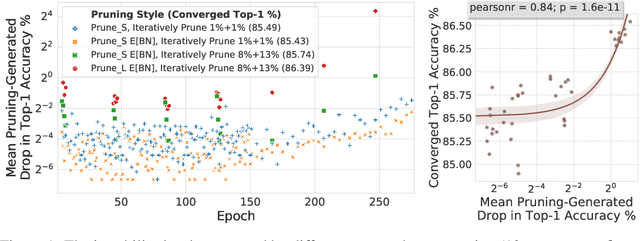
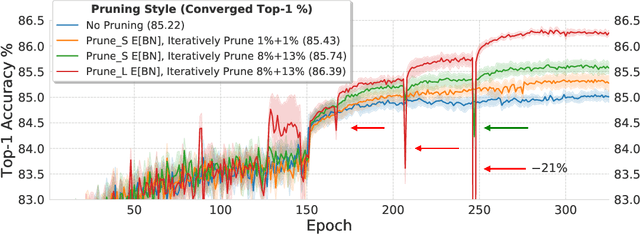
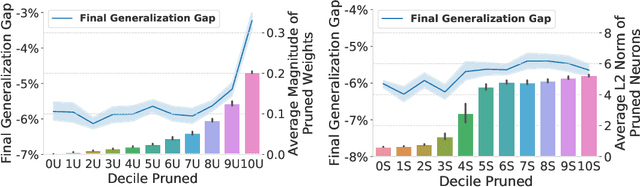
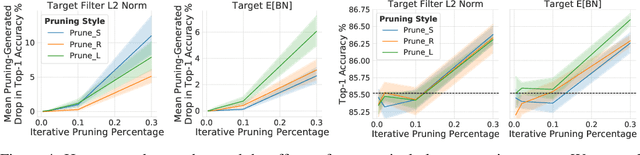
Pruning neural network parameters to reduce model size is an area of much interest, but the original motivation for pruning was the prevention of overfitting rather than the improvement of computational efficiency. This motivation is particularly relevant given the perhaps surprising observation that a wide variety of pruning approaches confer increases in test accuracy, even when parameter counts are drastically reduced. To better understand this phenomenon, we analyze the behavior of pruning over the course of training, finding that pruning's effect on generalization relies more on the instability generated by pruning than the final size of the pruned model. We demonstrate that even pruning of seemingly unimportant parameters can lead to such instability, allowing our finding to account for the generalization benefits of modern pruning techniques. Our results ultimately suggest that, counter-intuitively, pruning regularizes through instability and mechanisms unrelated to parameter counts.