 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-image guided Diffusion Model for generating Deepfake celebrity interactions
Paper and Code
Sep 26, 2023
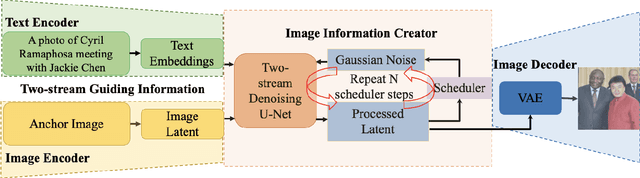
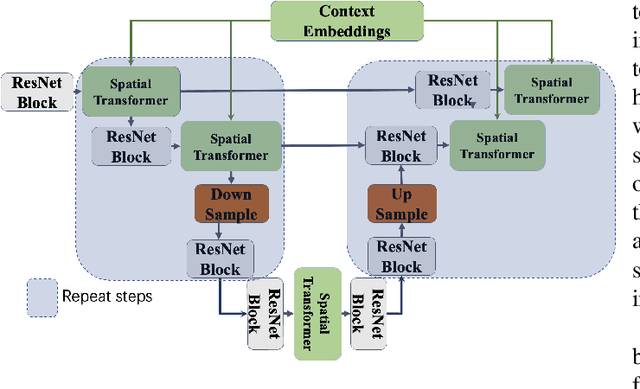
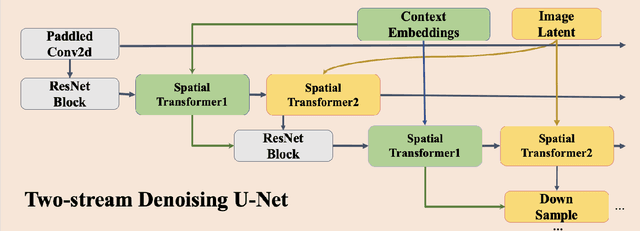
Deepfake images are fast becoming a serious concern due to their realism. Diffusion models have recently demonstrated highly realistic visual content generation, which makes them an excellent potential tool for Deepfake generation. To curb their exploitation for Deepfakes, it is imperative to first explore the extent to which diffusion models can be used to generate realistic content that is controllable with convenient prompts. This paper devises and explores a novel method in that regard. Our technique alters the popular stable diffusion model to generate a controllable high-quality Deepfake image with text and image prompts. In addition, the original stable model lacks severely in generating quality images that contain multiple persons. The modified diffusion model is able to address this problem, it add input anchor image's latent at the beginning of inferencing rather than Gaussian random latent as input. Hence, we focus on generating forged content for celebrity interactions, which may be used to spread rumors. We also apply Dreambooth to enhance the realism of our fake images. Dreambooth trains the pairing of center words and specific features to produce more refined and personalized output images. Our results show that with the devised scheme, it is possible to create fake visual content with alarming realism, such that the content can serve as believable evidence of meetings between powerful political figures.