 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Efficient Vision Transformer for Video Instance Segmentation
Paper and Code
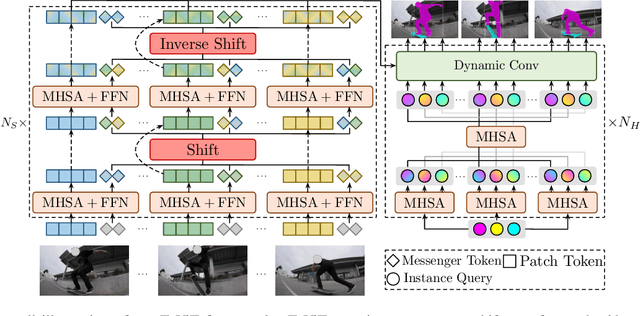
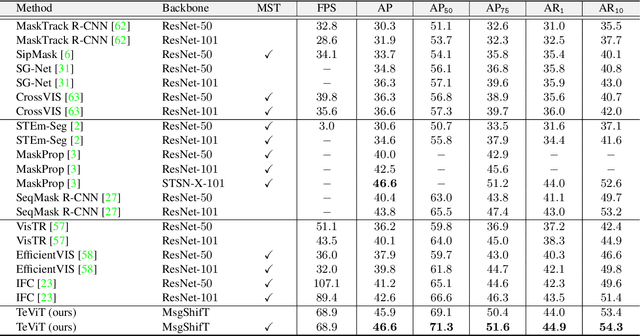
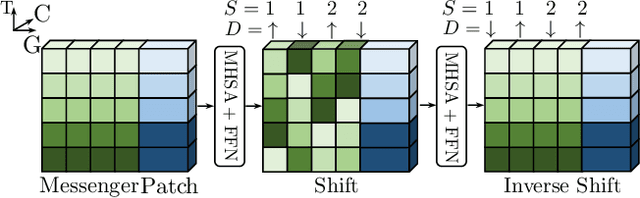
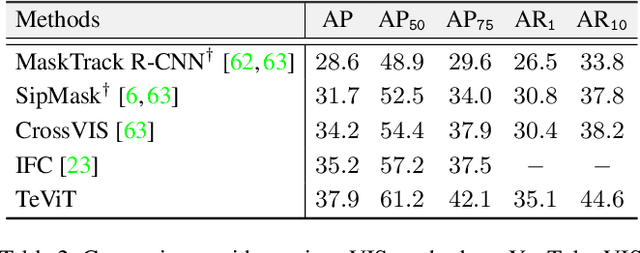
Recently vision transformer has achieved tremendous success on image-level visual recognition tasks. To effectively and efficiently model the crucial temporal information within a video clip, we propose a Temporally Efficient Vision Transformer (TeViT) for video instance segmentation (VIS). Different from previous transformer-based VIS methods, TeViT is nearly convolution-free, which contains a transformer backbone and a query-based video instance segmentation head. In the backbone stage, we propose a nearly parameter-free messenger shift mechanism for early temporal context fusion. In the head stages, we propose a parameter-shared spatiotemporal query interaction mechanism to build the one-to-one correspondence between video instances and queries. Thus, TeViT fully utilizes both framelevel and instance-level temporal context information and obtains strong temporal modeling capacity with negligible extra computational cost. On three widely adopted VIS benchmarks, i.e., YouTube-VIS-2019, YouTube-VIS-2021, and OVIS, TeViT obtains state-of-the-art results and maintains high inference speed, e.g., 46.6 AP with 68.9 FPS on YouTube-VIS-2019. Code is available at https://github.com/hustvl/TeViT.