Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeCS: A Dataset and Benchmark for Tense Consistency of Machine Translation
Paper and Code
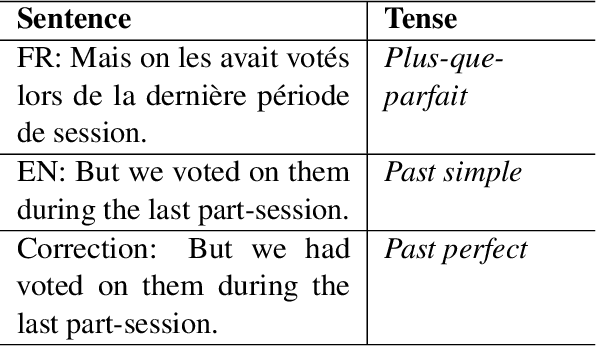

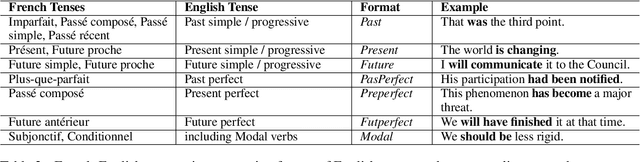
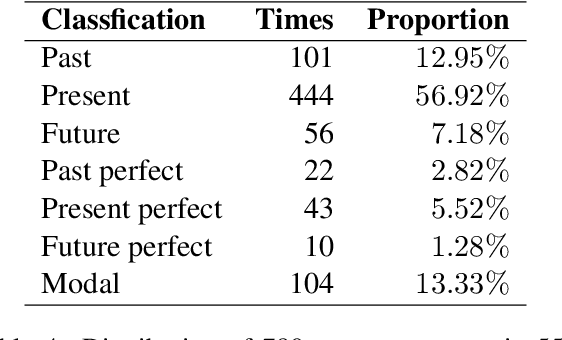
Tense inconsistency frequently occurs in machine translation. However, there are few criteria to assess the model's mastery of tense prediction from a linguistic perspective. In this paper, we present a parallel tense test set, containing French-English 552 utterances. We also introduce a corresponding benchmark, tense prediction accuracy. With the tense test set and the benchmark, researchers are able to measure the tense consistency performance of machine translation systems for the first time.
* 10 pages, accepted in main conference of ACL 2023
View paper on